Single Origin Platform, Part 1: Development Principles

In this series on the Single Origin platform, we do a deep dive into how we empower data operators to collaborate and work more efficiently. Part 1 of the series focuses on explaining some of the principles that guide the platform's development.
Background
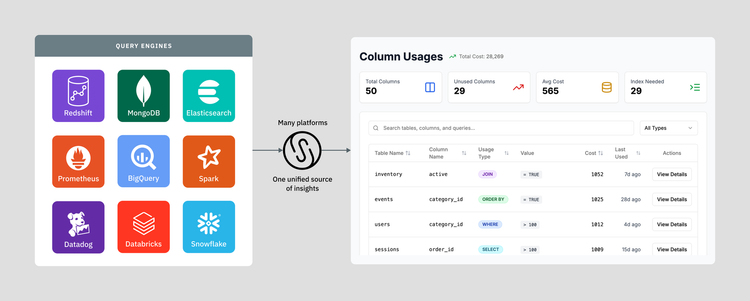
Let's recap the type of problems Single Origin is helping data operators solve. We believe that data stacks have a fragmentation problem and that efficient collaboration and reliable insights require standardized definitions. Thus, we are currently focused on the following three areas:
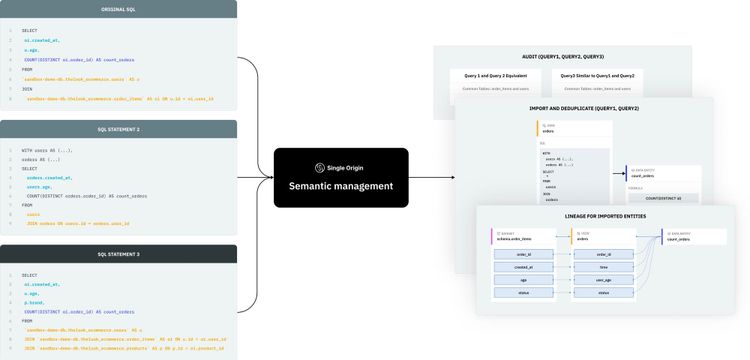
- Simplify your data stack: when you import SQL queries into Single Origin to build your data repository, we break the SQL down using a common definition model. This allows us to algorithmically dedupe similar definitions, which reduces complexity by ensuring the uniqueness of definitions and increasing reusability.
- Improve collaboration: when you import SQL queries into Single Origin to build your data repository, we ensure proper ownership, naming, and entity descriptions. We then add imported entities to a catalog where users can search for the concept they care about (instead of searching through tables that might have the information they need). Operators can share context around a concept and its use without worrying about technical details.
- Generate insights faster: once entities are defined in Single Origin, they can be queried in various ways, either in the Single Origin app or in your existing apps by integrating with our APIs. The uniqueness of definitions ensures that there is no ambiguity in the underlying logic, and by doing management in one place, you can ensure consistent access to data.
Principles
Given the background above, what are some principles that guide us when building solutions?
- Interoperability: one implication of our focus on collaboration and standardization is interoperability. If data operators need to stay on the same page, they need to work in the same application. Since Single Origin sits between pipelines (datasets) and analyses (dashboarding, visualization, and experimentation tools), it needs to support as many import options as possible so that data operators can generate definitions from any of their tools. Many data processing tools generate compiled SQL (Airflow, Apache Spark, dbt, etc.), so we have put a lot of effort into enabling users to import standard SQL statements from various sources.
- Reusability: one implication of our focus on simplifying your data stack is reusing as much as possible, and we increase reusability with algorithmic deduping. Data operators should not need to know every concept in their database, so Single Origin automatically finds duplicates for users. We have enterprise-ready infrastructure that supports parsing hundreds of queries per minute and extracting unique definitions.
- Support all data operators: data operators have various backgrounds, leading to a variance in technical skills. Since some data operators are not comfortable working in code editors, we are investing in an easy-to-use UI to onboard as many operators as possible and get them collaborating. We want the Single Origin application to feel comfortable for both technical and non-technical users, which means users must be able to interact without necessarily knowing details about SQL, tables in a warehouse, YAML files, etc.
- Codify best practices: we want Single Origin to be a scalable platform that your company can use for years. Single Origin is built by experienced developers who have worked on best-in-class solutions for various companies. We do not want to leave it up to users to figure out the best management practices for their data, so we highlight these in code. For example, we have validations on imports, a (lightweight) review process for creating/modifying definitions, and a change log for all your entities. Sometimes this may feel like extra work, but we believe it will save companies significant time and money in the long run by avoiding confusion, massive cleanup efforts, etc.
Conclusion
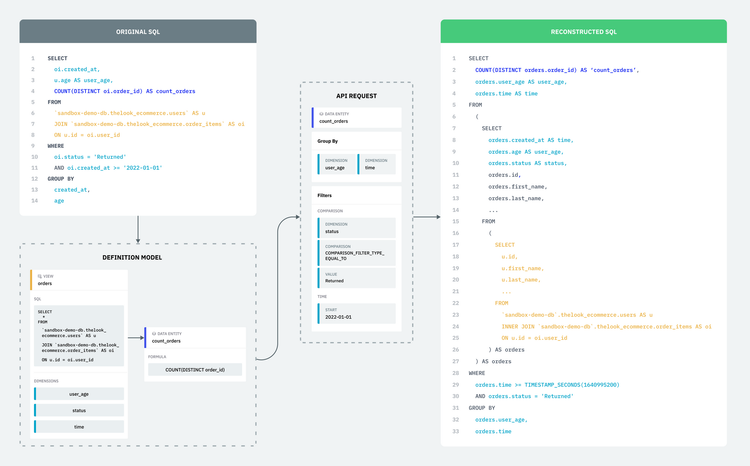
Hopefully, you now have a better sense of what problems Single Origin is focusing on and how Single Origin is building solutions. Check back soon for Part 2 of our series, where we will do a technical dive into Single Origin's common definition model. We will show you how Single Origin breaks down SQL queries and then rebuilds them when users want to query their data. As always, feel free to reach out with any feedback or questions!