Single Origin Platform, Part 2: Deconstructing SQL queries into Reusable Components
In this series on the Single Origin platform, we do a deep dive into how Single Origin empowers data operators to collaborate and work more efficiently. In this article, we will break down how we deconstruct a SQL query into reusable components with Single Origin’s common definition model. We will then walk through the process of reconstructing that query from its reusable components.
Background
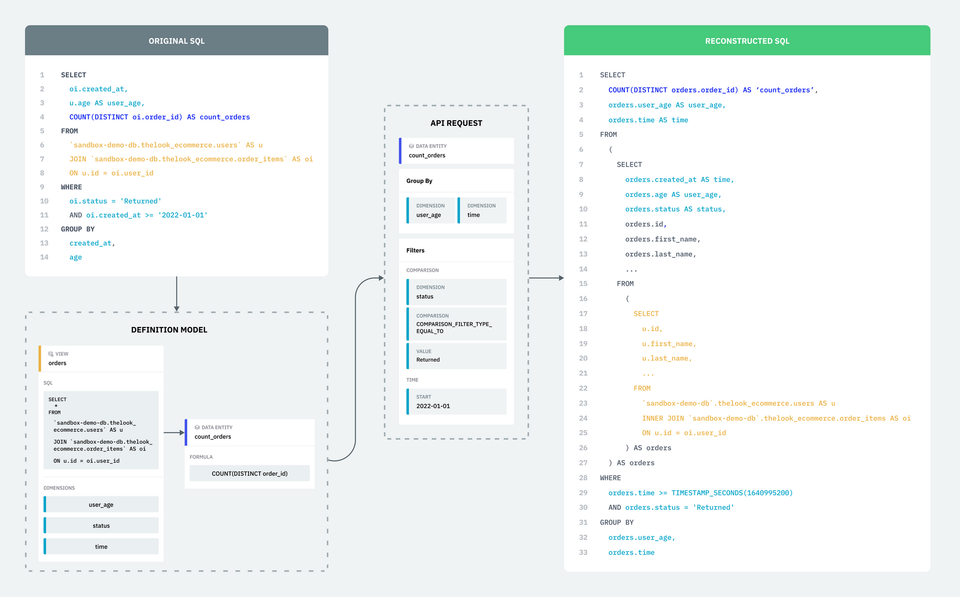
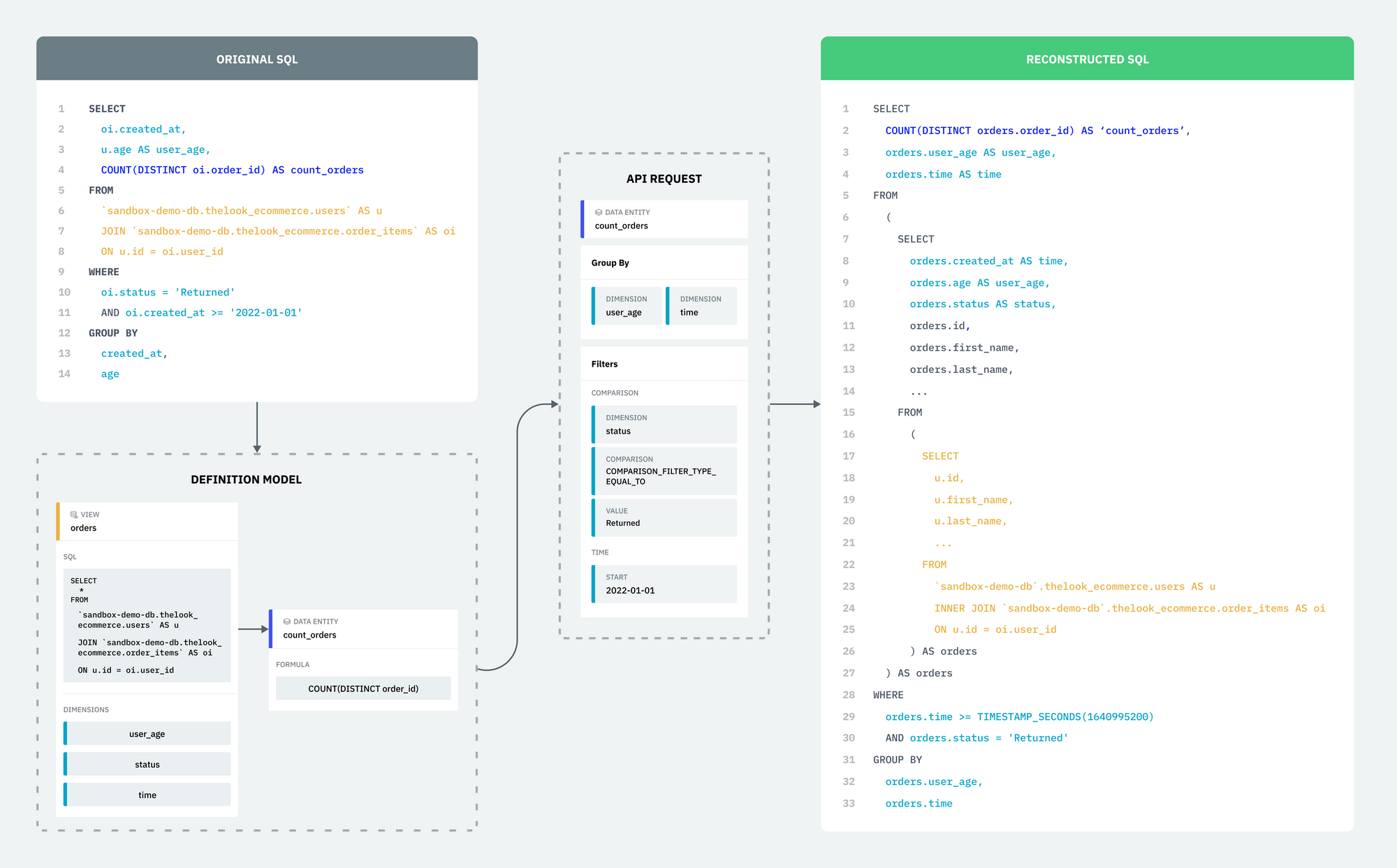
In part 1 of our series, we discussed how unmanaged data queries could lead to unreliable data insights and stall collaboration efforts. We also shared the principles that shape our solution to this pervasive problem. A cornerstone of our solution is our common definition model, which enables the standardization of key data parts. We illustrated this model through a case study examining a frequently executed query that tracked the number of items returned by customer age. Now, we will take a look at how Single Origin deconstructs SQL queries into models that can be reconstructed into semantically equivalent queries.
Deconstructing the Query

Single Origin leverages Apache Calcite to parse imported SQL queries into abstract syntax trees (ASTs). The ASTs are then converted into the common definition model. In the process, Single Origin traverses 4 node types in the AST:
- FROM Clause (View)
- GROUP BY Groupings (Dimensions)
- WHERE Filters (Dimensions)
- SELECT Items (Data Entities)
FROM Clause (View)
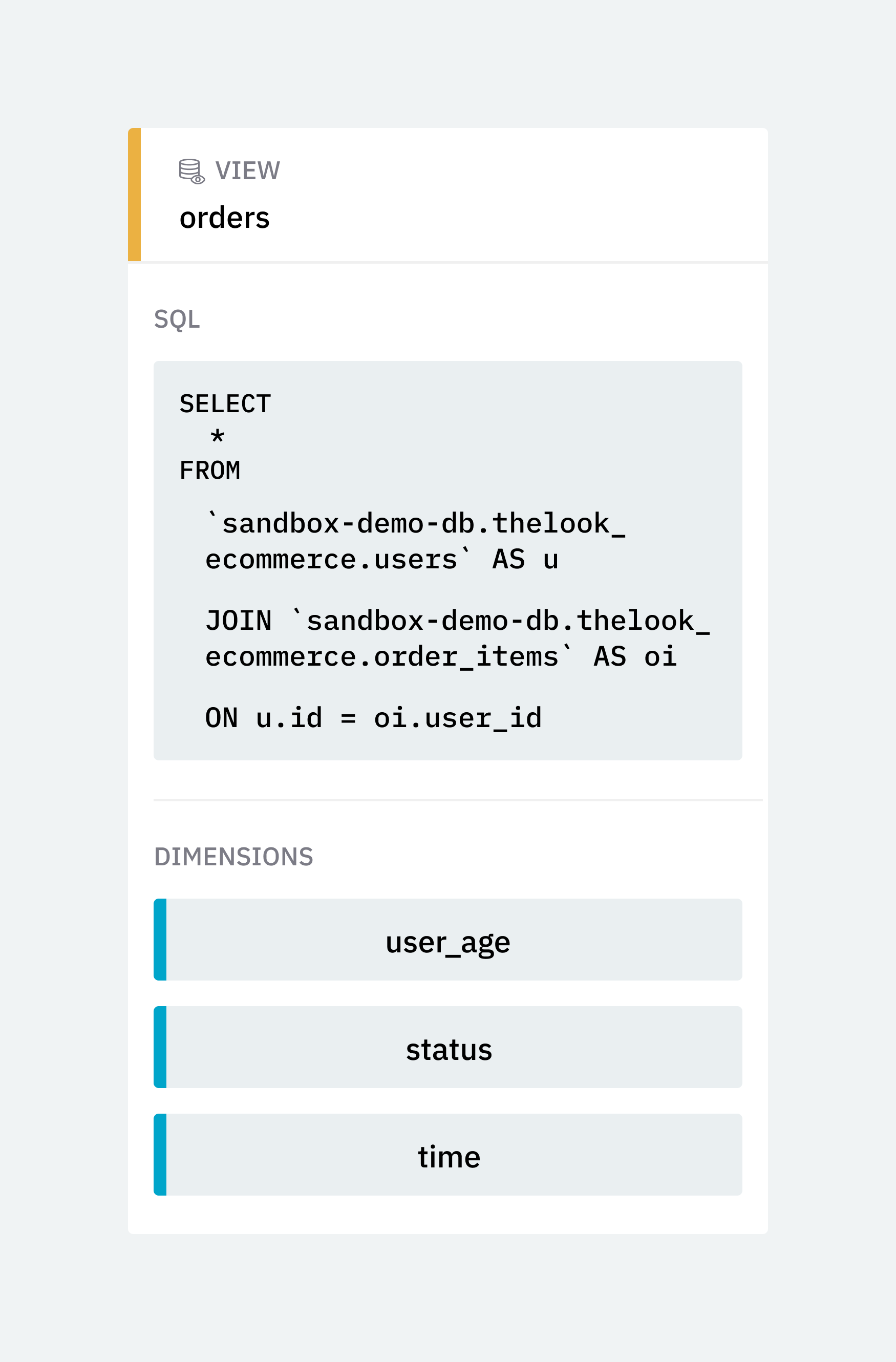 In a SQL query, FROM clauses are used to identify which datasets to operate on. Likewise, Single Origin uses the FROM clause as the base dataset on which current and future SQL queries can be built. We extract the FROM clause and turn it into a view by
In a SQL query, FROM clauses are used to identify which datasets to operate on. Likewise, Single Origin uses the FROM clause as the base dataset on which current and future SQL queries can be built. We extract the FROM clause and turn it into a view by SELECT * the FROM clause.
After extraction, the FROM clause becomes a reusable source. Additionally, because all columns are selected from the table, upstream table changes are automatically reflected in the resulting view.
SELECT Items (Data Entities)
 SELECT items are categorized as aggregate or non-aggregate. Aggregate SELECT items are converted into named data entities, and are attached to the newly created view. Non-aggregate SELECT items will play a role later on, when dimensions are extracted from the GROUP BY groupings and WHERE filters.
SELECT items are categorized as aggregate or non-aggregate. Aggregate SELECT items are converted into named data entities, and are attached to the newly created view. Non-aggregate SELECT items will play a role later on, when dimensions are extracted from the GROUP BY groupings and WHERE filters.
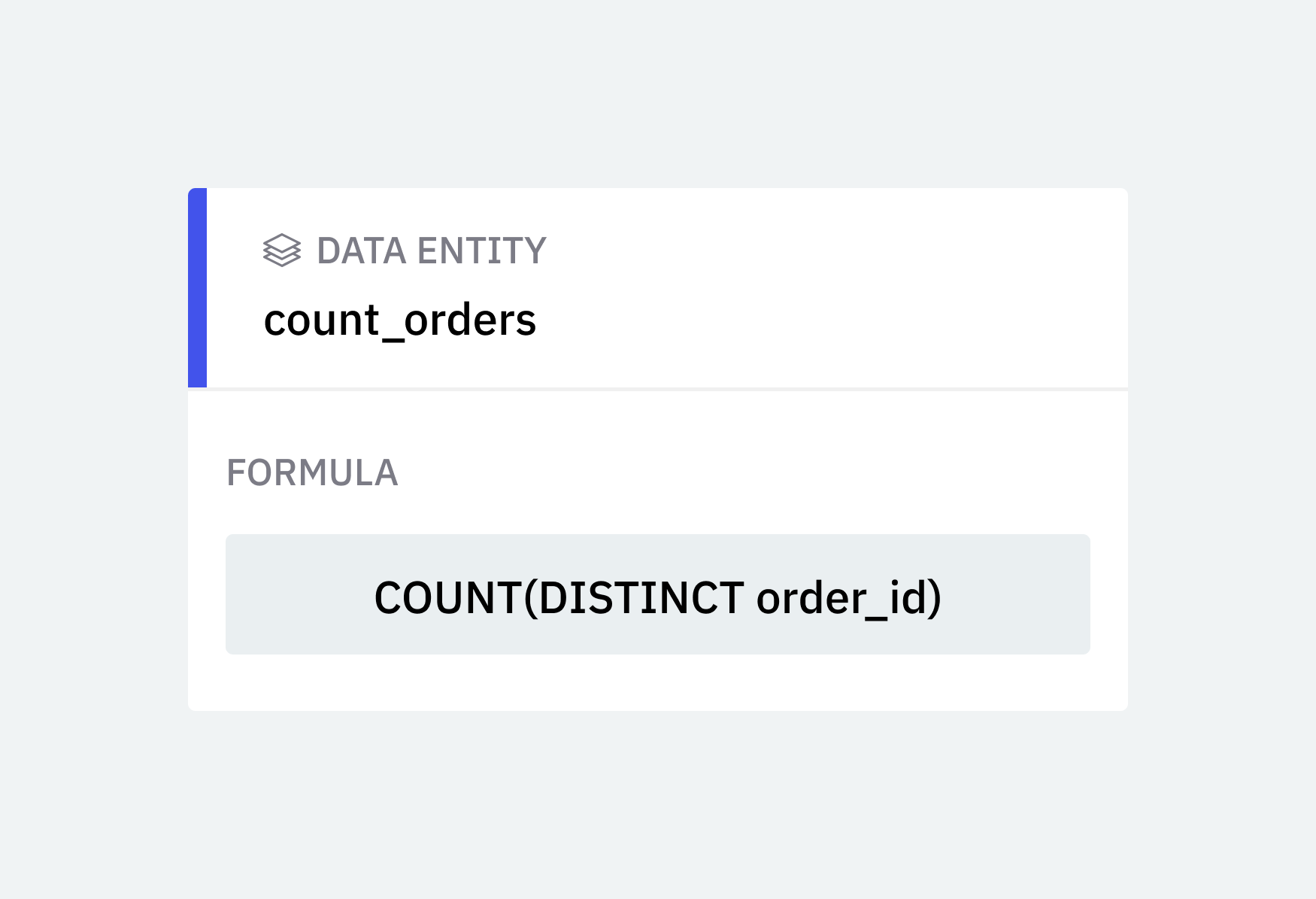
In our example, there is only one aggregate select item:
COUNT(DISTINCT oi.order_id) AS count_orders
Single Origin extracts two pieces of information from this SELECT item: the expression and a name for it. In the above SQL expression, the expression to the left of AS is the data entity formula, and to the right of AS is the identifier, which is used as the data entity's name. When no name is provided, one is generated based on the expression.
This extraction process names each expression formula. Data operators can then use these names to specify data they want to analyze, without knowing exactly how to compute the data, or which source is used in the computation.
GROUP BY Groupings & WHERE Filters (Dimensions)
GROUP BY groupings define how data is segmented, and WHERE filters narrow down the data analysis to specific segments. These data segmentations often share a common definition from their source, and are labeled with a canonical name. We define these data segmentations as dimensions.
There are two types of dimensions in Single Origin: local and standardized. Local dimensions are attached to a single view, while standardized dimensions can be common across many views. Both types of dimension are extracted in similar ways.
In this example, we have four GROUP BY and WHERE SQL expressions:
WHERE
oi.status = 'Returned'
AND oi.created_at >= '2022-01-01'
GROUP BY
created_at,
age
Single Origin will break down each expression into two pieces of information: the dimension expression itself, and the name of that dimension. The dimension expression is extracted from the GROUP BY and WHERE expressions. The dimension name is derived from the non-aggregate SELECT items mentioned earlier. The extracted expressions are cross-referenced with the non-aggregate SELECT items, linking names to expressions. When an alias is provided for an expression, it is used as the dimension name. If no alias is provided, names are generated based on the expression. The dimensions are then added to the view "orders".
| Dimension Name | Type | Expression |
|---|---|---|
| user_age | local | age |
| status | local | status |
| time | standardized | created_at |
You may notice that for the expression created_at, Single Origin mapped a name to it that wasn't in the original query. That's because Single Origin uses a special standardized dimension, "time". This dimension represents a time entry in a given row.
Reconstructing the Query
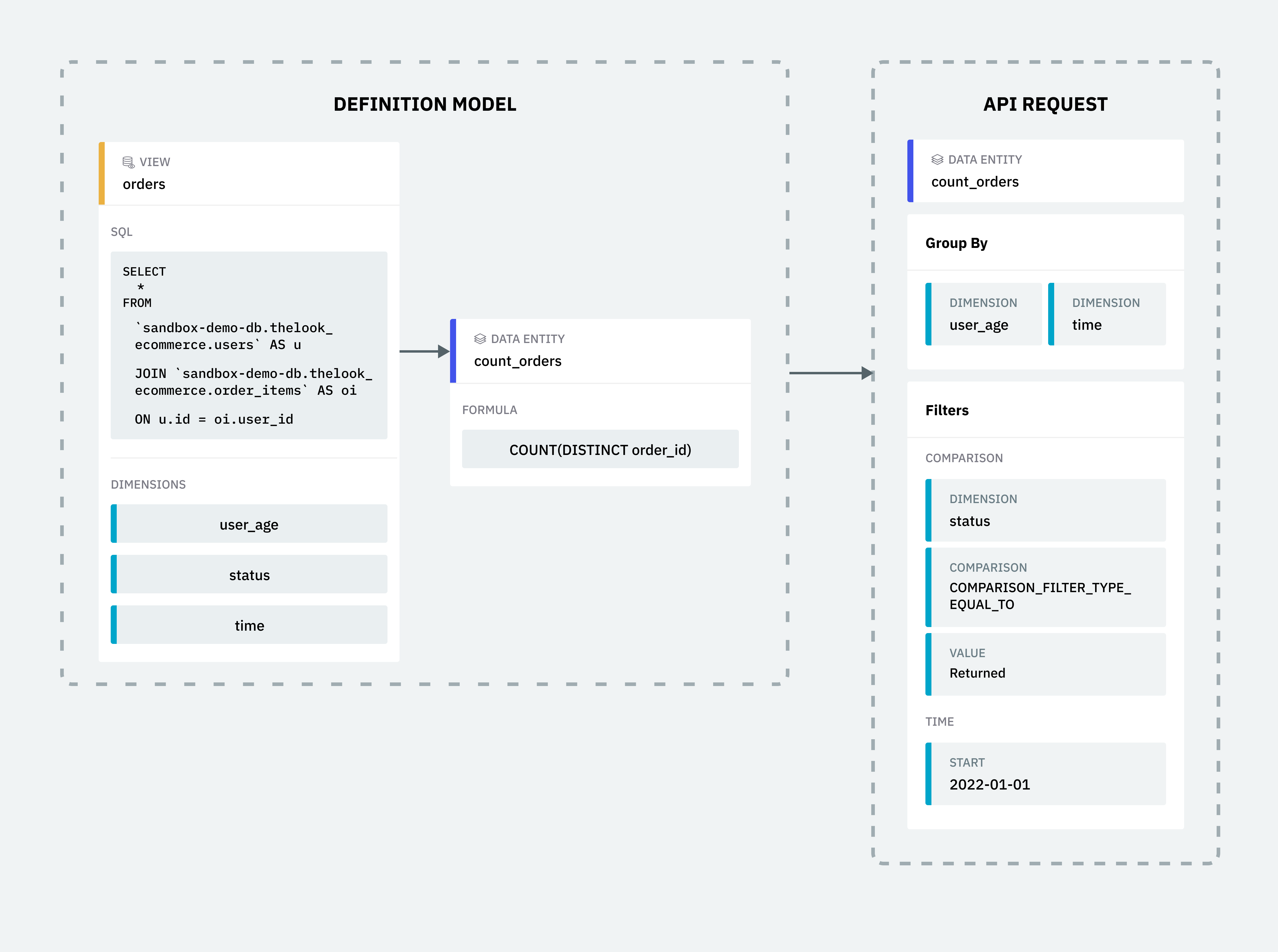
Now that the query is deconstructed into a definition model of views, dimensions and data entities, Single Origin can reconstruct the original query using our SQL generator API.
Recreating the original query can be done though Single Origin's UI or API. Below is an example using the API.
{
“dataEntityNames”: [
“count_orders”
],
“groupBys”: [
{
“simple”: {
“dimensionName”: “user_age”
}
},
{
“simple”: {
“dimensionName”: “time”
}
}
],
“filters”: [
{
“comparison”: {
“dimensionName”: “status”,
“comparison”: “COMPARISON_FILTER_TYPE_EQUAL_TO”,
“value”: “Returned”
}
},
{
“time”: {
“start”: “2022-01-01”
}
},
]
}
Data Entities
Data entities define both the expression formula and the source to use. Because of this, a simple query can be built using the name of the data entity and its associated view. Single Origin then adds dimensions identified by the source to the target view.
SELECT
COUNT(DISTINCT orders.order_id) AS `count_orders`,
FROM
(
SELECT
orders.created_at AS time,
orders.age AS user_age,
orders.status AS status,
...
FROM
(
SELECT
...
FROM
`sandbox-demo-db`.thelook_ecommerce.users AS u
INNER JOIN `sandbox-demo-db`.thelook_ecommerce.order_items AS oi
ON u.id = oi.user_id
) AS orders
) AS orders
The above SELECT item expression is derived from the given data entity, while the FROM query is found in the view SQL linked to the data entity. All dimension expressions defined on the view are then added to the source query.
Group Bys
In our request, we have two dimensions we want to group by: user_age and time. Single Origin converts this request to SQL by selecting and grouping by the names of the dimensions. The expressions associated with these dimension names have already been inserted as part of the source view.
SELECT
orders.age AS age,
orders.time AS time
GROUP BY
orders.age,
orders.time
Filters
Lastly, our request has two filters: one comparison filter and one time filter. Single Origin converts the two filters to SQL as requested. The dimensions name is used instead of the expression, similar to how Single Origin handles group bys.
WHERE
orders.time >= TIMESTAMP_SECONDS(1640995200)
AND orders.status = 'Returned'
Final Result
Now that each section of our request has been translated into their equivalent SQL queries, Single Origin can combine all of the SQL generated into one SQL query.
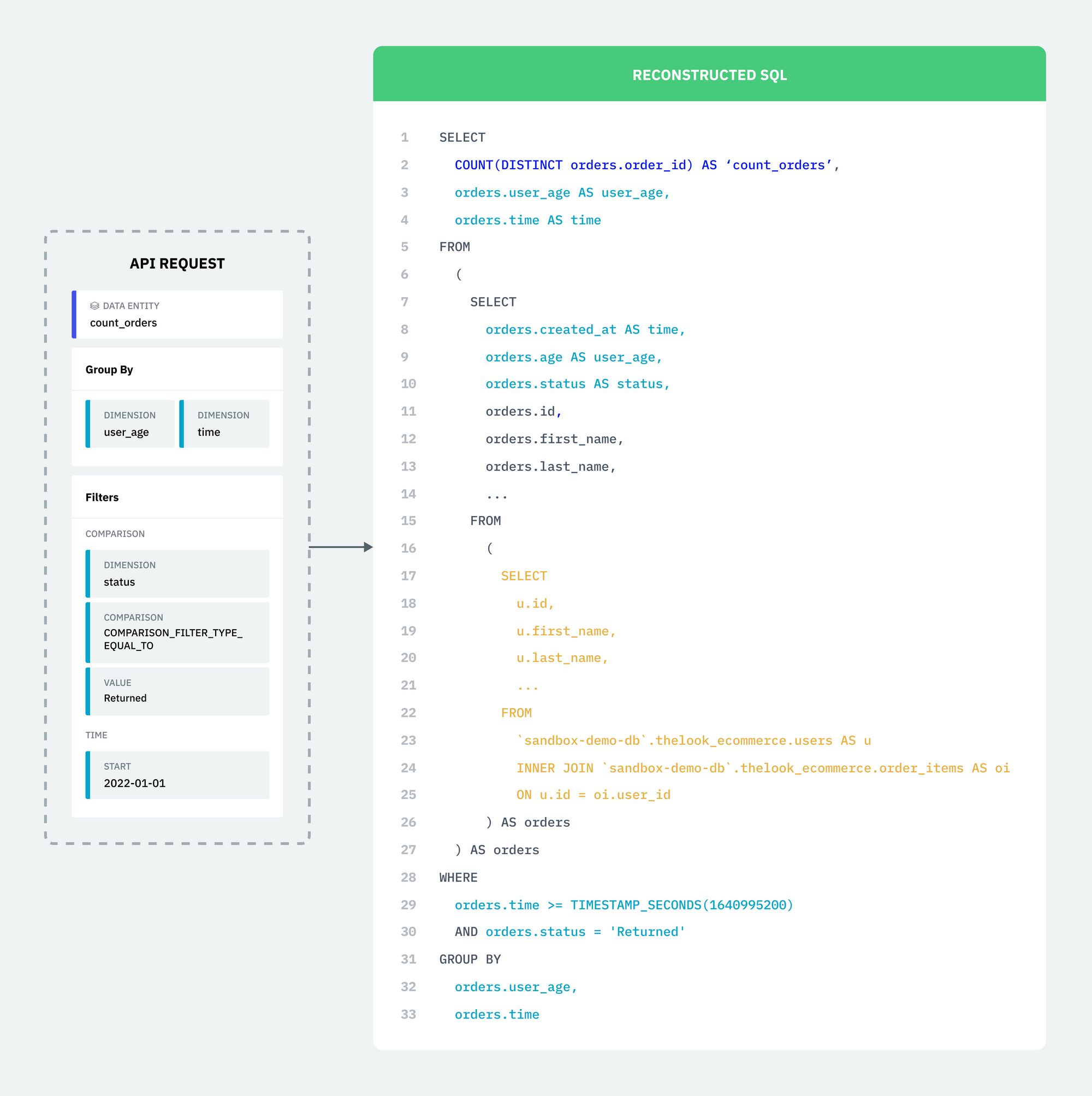
If we compare the generated SQL with the SQL we deconstructed earlier, we can see that the two SQL queries are semantically equivalent.
Conclusion
Deconstructing the original SQL into our common definition model has several advantages for consumers and producers:
- Users do not need to understand which source data to use or how to craft the right expression to get the data they need. They only need to know the name of the entity they want to query with.
- Our common definition model enables standardized definitions which can be used to slice and dice data for other data exploration use cases. Different filters and group bys on dimensions can be combined to query data without having to manually modify SQL queries.
Tune in next time for part 3 of our series where we dive into how we apply semantic management to our common definition models!