Single Origin Platform, Part 3: Semantic Management Powers Novel Applications
Welcome back to our three-part series on the Single Origin platform. In this series, we've explained what problems Single Origin solves and demonstrated how SQL queries are deconstructed into a common definition model, allowing them to be reconstructed into reusable components. Today, we will look at how Single Origin defines and implements a semantic management system. Then, we’ll look at some of the novel features Single Origin offers through its unique approach to semantic management.
Semantic Management
Given that semantic management is a relatively new field, let's begin with a quick definition. Then we’ll examine why adopting a semantic management tool is crucial for data-intensive organizations to efficiently scale and collaborate.
In the context of this article, data semantics are all about the meaning of data, like what it is and how to use it, under different business contexts. One way to imbue this meaning is through data definitions. Semantic management, then, is the collecting, refining, governing and consuming of data definitions within an organization. Semantic management is the key to simplifying your data stack, improving collaboration across company verticals and generating higher quality insights from your data, faster.
One way semantic management achieves this is through embedding definitions and meaning into data pipelines and workflows. This alignment of meaning across an organization enriches SQL queries for both humans (e.g., business operations) and machines (e.g., machine learning features).
Why SQL Semantics?
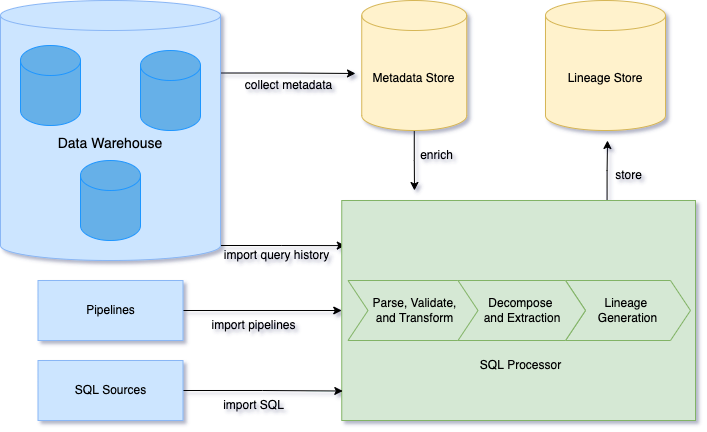
Single Origin relies on SQL expressions to define and communicate the meaning of data. SQL was an easy choice, as it is widely used in data analysis and supported by every cloud vendor/data processing engine. In addition, it is expressive and extensible, and its semantics can be formulated as relational algebra, making comparisons between different SQL statements possible. Single Origin uses the open source Calcite to parse, process and relate SQL queries.
Single Origin Data Semantic Management
In Single Origin, data semantics consist of three parts: definition model, SQL-based calculation logic, and domain knowledge rule. In practice, the common definition model abstracts away the calculation logic and domain knowledge rule, leaving a simple and familiar interface for users. Now, we’ll take a look at each of the three parts in detail.

Common Definition Model
Single Origin's common definition model is composed of views, dimensions, and data entities. Through this common definition model, business terms are mapped to the underlying data. This makes your data accessible and functional for internal consumers, without requiring them to understand the SQL expressions used or specific domain knowledge. This standardization aligns the meaning of your data across every stakeholder - from business operators to data scientists.
The common definition model offers several benefits to data operators:
- reducing or even removing any learning curve for data operators, as they no longer need to understand the underlying logic behind their queries;
- hiding away the complexity of underlying data systems, making them easily detachable for specific cloud vendors or data engines;
- simplifying updates to definitions by automatically populating the changes to all downstream entities;
- connecting views, data entities, dimensions and datasets through relationships, allowing unprecedented insight into data pipeline infrastructure.
SQL-based Calculation Logic
Views and data entities are defined with SQL expressions to represent their calculation logic. Single Origin leverages SQL semantics to automatically manage calculation logic. The platform defines relational and lineage algebra properties for use in arithmetic calculations. Based on these properties, Single Origin can automatically derive an equivalence, and a similarity score, between any two SQL expressions. Data operators can then use this insight to remove inefficiencies, consolidate pipelines and prevent the accidental use of two similar, but not identical, SQL statements to calculate the same business heuristic.
Domain Knowledge Rule
The last element of Single Origin’s data semantic is domain knowledge rules that capture business domain knowledge and embed that knowledge into the data management system. Here are some examples:
- Time interval knowledge such as 1 day = 24 hours. This is common to all the business metrics based on the time series data. With this knowledge, we could derive the relation between data with different time intervals on the same metric.
- Product hierarchy knowledge: some companies organize the product as business lines which have several sub-products under each line. This is helpful for the data operator to slice and dice the business metrics more efficiently.
- Data category knowledge such as certain datasets is financial related. With that, we could tag all the downstreaming data entities as financial related, which is helpful for data operators to explore data and admin to manage data access.
- General Data Protection Regulation (EU GDPR) could be enforced through a domain knowledge rule. All the PII data can be marked based on the business domain knowledge and populated across all entities to ensure the regulation.
Domain knowledge is especially critical when it comes to how the data can be better used. Here are some aspects of how domain knowledge improve the data usage
- Optimization - The domain knowledge enables us to rewrite the query to improve the overall query performance and save cost. For example, if there is a table stored precomputed result on sub-product level, we can roll up that to the business line level rather than computing from the raw table.
- Consumption Management - Domain knowledge rules regulate how data operators could consume the data. For example, based on the GDPR rule or data category, we could enable only certain users to consume certain business metrics in certain segments.
Semantic Management System
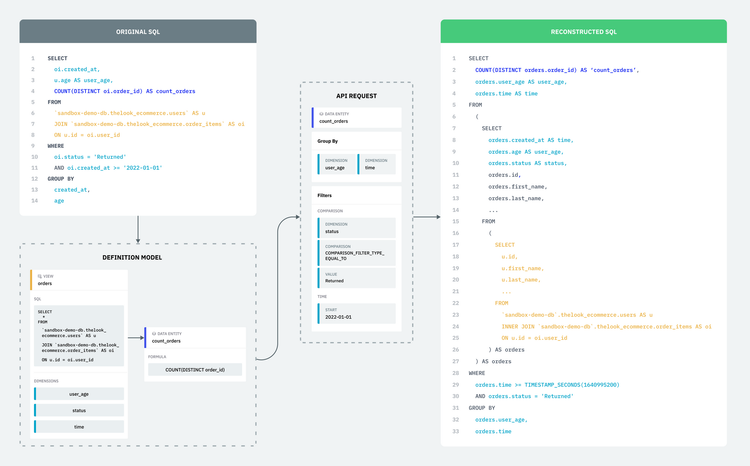
Single Origin’s semantic management system collects user inputs, like analytical SQL statements and domain knowledge and converts it to a definition model with terms familiar to most users. This management avoids duplication and ambiguity around data definitions. Single Origin serves as a bridge between data operators and the underlying data analysis to enable consumption without knowledge of the full technical context. The diagram below shows the five steps involved in transforming SQL statements to user facing entities.

WITH
users AS (
SELECT
id AS user_id,
age AS user_age
FROM (
SELECT
*
FROM
`db.schema.users` ) AS users ),
orders AS (
SELECT
user_id,
created_at AS created,
order_id AS id
FROM
`db.schema.order_items`
WHERE
status = 'Returned'
AND created_at >= '2022-01-01' )
SELECT
created,
user_age,
COUNT(DISTINCT id) AS count_orders
FROM
users
JOIN
orders
ON
users.user_id = orders.user_id
GROUP BY
1,
2 For brevity, we replace the concrete project and dataset name with db.schema and skip the prefix in the examples.
Parse, Validation, and Transformation
Single Origin parses SQL into AST (abstract syntax tree) and leverages Calcite to validates the AST based on relevant dataset schema. During the validation process, the scope of each syntax node is derived and verified, ensuring a higher level of accuracy than parsing alone. When two or more nodes have the same name, the correct context for each is attached to the nodes by the validator. Additionally, if it is unclear which dataset a column comes from, then the validator can derive and extend the node's source prefix. With the correct context and source prefix, the underlying source for any node can be easily identified.
For example, the above SQL statement has two sub-queries with the name users, but they have different exposed columns. For the outermost query, Calcite knows the users pointing to the with clause item users with user_id and user_age. The outermost query selection items user_age and created_at don’t have a prefix to tell where they are from, but Calcite extends them as users.user_age and orders.created_at during the validation process.
After the parsing and validation, we leverage the relational operator properties to transform the original SQL AST to another canonical form AST where all the expressions are directly based on the underlying physical table. The following SQL statement is output after canonical transformation.
SELECT
`db.schema.order_items`.created_at AS created_at,
`db.schema.users`.age AS user_age,
COUNT( DISTINCT `db.schema.order_items`.order_id ) AS count_orders
FROM
`db.schema.users`
JOIN
`db.schema.order_items`
ON
`db.schema.users`.id = `db.schema.order_items`.user_id
WHERE
`db.schema.order_items`.status = 'Returned'
AND `db.schema.order_items`.created_at >= '2022-01-01'
GROUP BY
`db.schema.order_items`.created_at,
`db.schema.users`.ageDecomposing and Extraction
During the decomposition process, the transformed SQL AST is broken into four parts: source, selection items, where clause, and group by. All these decomposed items are used later for the lineage generation. The SQL above generates the following items:
| Source | `db.schema.users`
JOIN
`db.schema.order_items`
ON
`db.schema.users`.id = `db.schema.order_items`.user_id |
|---|---|
| Selection Items | `db.schema`.created_at,
`db.schema`.age,
COUNT( DISTINCT `db.schema.order_items`.order_id ) |
| Where Clause | `db.schema`.status = 'Returned'
AND `db.schema.order_items`.created_at >= '2022-01-01' |
| Group By | db.schema.order_items`.created_at,
`db.schema.users`.age
|
Embed Domain Knowledge
In the above example, one example of domain knowledge we could embed relates to the time dimension. Based on the extracted where clause, we identify the created_at as the primary time segment column. With this time dimension knowledge, data operators can later consume the data with any interval such as day, week, month, hour etc. Our semantic management can generate the corresponding interval expression with the created_at column.
SQL Analysis
SQL analysis is used to derive the relation between different SQL expressions based on the relational algebra operator comparison. Our SQL analysis is based on the transformed canonical form since it could eliminate the format difference. During the comparison, it recursively searches the equivalent/similar operators in the expression to compute the similarity score. Then it uses the similarity score to deduplicate the semantic equivalent SQL expression and make suggestions based on other high similar expressions.
Entity Generation

As you can see, the right part of the diagram demonstrates the generated entities. There is one view, one data entity and three dimensions. The entity SQL expression is not based on the canonical format since the canonical format is machine transformed and usually not read friendly. You can find more detail about how SQL is deconstructed into entities in our platform blog here.
Semantic Management Applications
Now that we understand the what and how, let’s examine some novel applications of Single Origin’s semantic management. In the following use cases, we continue using examples from previous tech blogs and some additional examples from our semantic validation page.
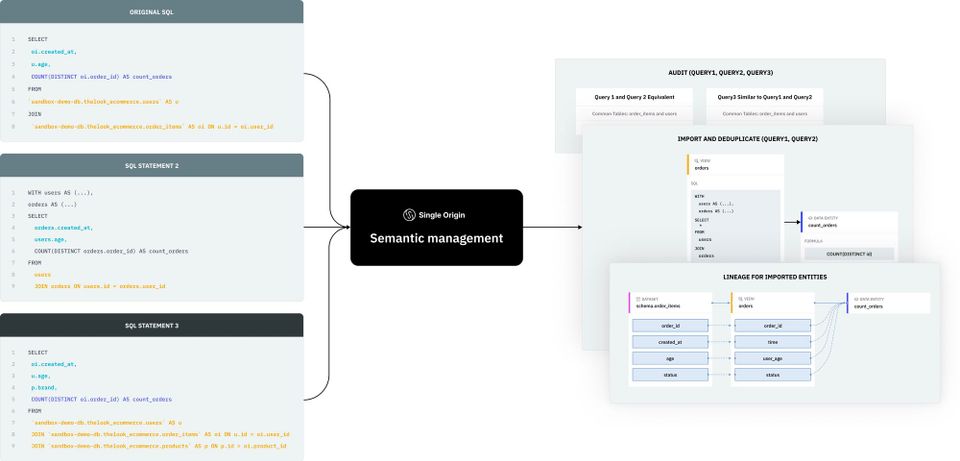
Take the following three statements. Single Origin leverages properties of relational operators rename and projection to rewrite the query into a canonical format, where statement 1 and 3 are kept untouched while statement 2 is converted to statement 1. After that, it can make an expression comparison to derive the relationship between the three statements.1 and 2 are semantic equivalent while 3 is semantic similar to both 1 and 2.
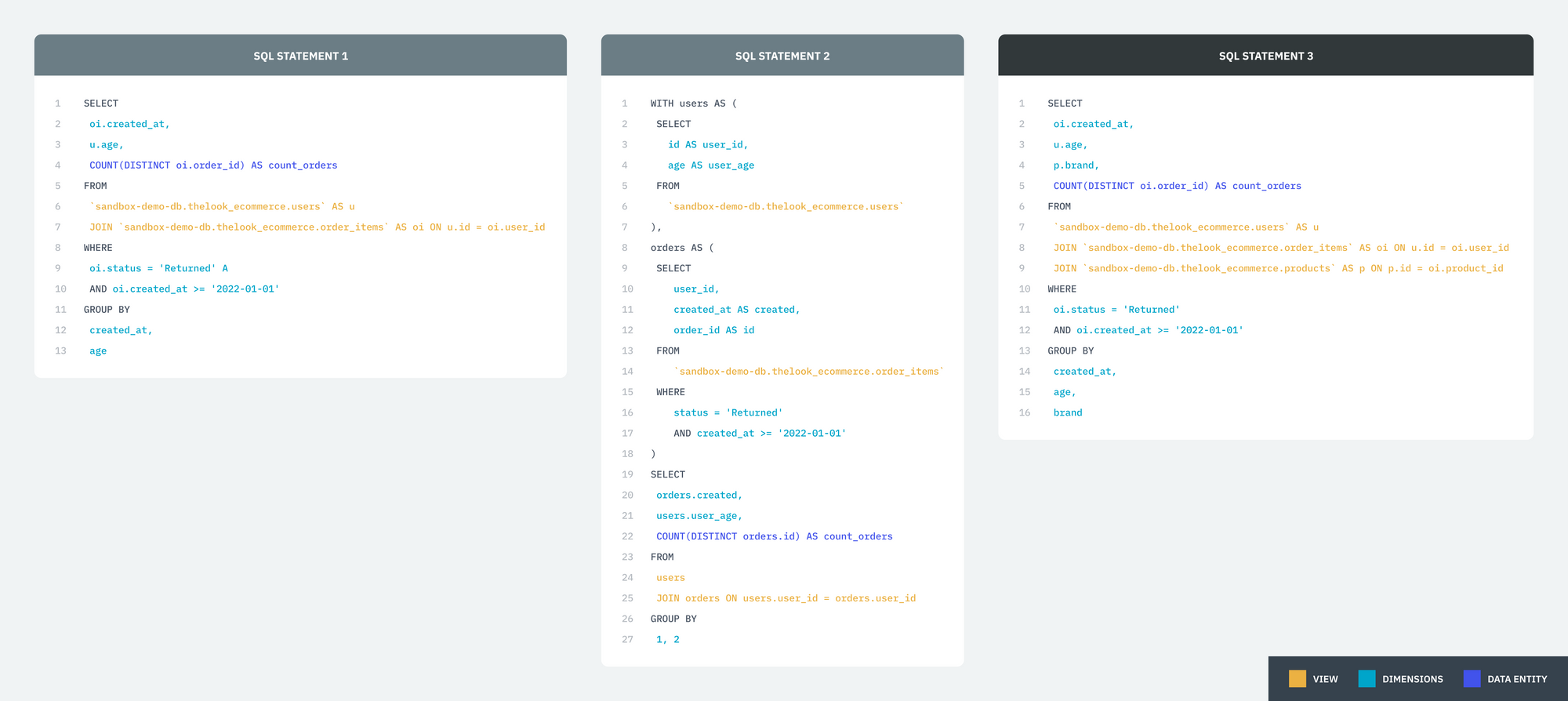
Query Audit
Query Auditing in Single Origin is a tool that Admins can use to get insight into what queries exist in their data warehouse. If you provide the above two statements to query audit and tag them as statement1 and statement2 separately, it will generate the following result. You can find more detailed explanations about the result in the audit page. This audit result enables the data operator to understand what exists in the data repository without requiring them to go through thousands of definitions.
| Group# | Type | Queries in Group | Common Datasets | Common Formulas |
|---|---|---|---|---|
| 1 | Exact | Statement1, Statement2 | db.schema.users, db.schema.order_items |
COUNT(DISTINCT order_items.order_id) |
| 2 | Similar | Statement1, Statement2, Statement3 | db.schema.users, db.schema.order_items |
COUNT(DISTINCT order_items.order_id) |
Entity Deduplication
Let’s use the above 3 statements to generate the entities in Single Origin through our import flow. The statement 1 generates view orders and data entity count_orders. When the statement 2 is processed, it will be automatically deduplicated and return a response to tell which entity can be directly reused and show the comparison of SQL statements to tell why it’s duplicated. For statement 3, it will generate a suggestion and ask user input to either ignore the suggestion or accept the suggestion of merging those two similar views into one. The above scenarios are very common when some new employees onboard and collaborate on the definition repository. Entity deduplication automatically highlights duplicates before it happens, helping you keep a clean structure and scale efficiently.
Field Level Lineage
Field level lineage is derived from the semantic management which links the query output fields to its underlying source fields. This is used to derive dataset field to dataset field lineage from the pipeline queries, view field to source dataset field lineage, and data entity to view field lineage. This deriving process relies on the relational operator properties based query rewriting to link the expression directly to underlying source datasets. Field lineage helps you understand how data flows through your system, which has a variety of benefits. More detail can be found in our lineage blog.
For the above statement 1, it generates the following entity lineage.

Conclusion
We're excited to share our work with you, and give you an idea of how Single Origin's semantic management system can enable data operators to collaborate, organize and streamline their data like never before. In the coming months, we plan to support more input sources, such as DBT and Spark jobs. We will also explore new and novel features in our platform, like data issue debugging. If you are interested in learning more, please reach out. Until next time!