Decoding Instacart's Data Strategy and Achieving Automated Data Efficiency with Single Origin

With 1,000 daily active users, 200 warehouses, 5 million active tables, and a whopping 230 million monthly queries, it's fair to say Instacart is a Snowflake power-user. Yet, according to Instacart's recent S-1 pre-IPO filing, Instacart's Snowflake spend is down significantly after reaching a peak of ~$28M in 2022.
Competitors like Databricks trumpeted the decline as a sign of softening demand for Snowflake at Instacart, but after speculation around the reported numbers reached a critical mass online, Snowflake released a short post explaining Instacart's shrinking cloud bill.
According to Snowflake, it's not a matter of usage but efficiency. This was further underscored by a tech talk released shortly after the S-1, featuring Rajpal Paryani, an ML Engineering Manager at Instacart, and Scott Redding, a Senior Solutions Architect at Snowflake. In the talk, they provide insights into how Instacart fine-tuned its Snowflake operations to improve performance and slash costs.
In this article, we'll look at Instacart's approach to optimizing queries. Then, we'll examine how you can achieve the same results in your data cloud for a fraction of the time and effort using the semantic management platform Single Origin.
Instacart's Process
Instacart's approach to query efficiency revolves around observability and accountability. Observability encompasses collecting and monitoring query-level metrics (cost, latency, bytes scanned, etc.). Accountability refers to assigning expensive or inefficient queries to individuals for remediation.
First, the data platform team manually tags and fingerprints queries. This query tagging and fingerprinting process is used in conjunction with custom dbt packages to generate query-level metric tables and dashboards. These query-level metrics are continuously monitored - when expensive queries are identified, they are assigned to Directly Responsible Individuals (DRIs). It's up to these individuals to use tools like Snowflake's Query Profiler to optimize their queries on a workload-by-workload basis. This process is repeated as new queries are written and old queries are refactored.
You may notice that this approach requires a lot of consistent, disciplined, manual effort to deliver on the promise of increased efficiency. The tagging, fingerprinting, monitoring, assigning, and rewriting of SQL queries is a massive ongoing investment. Instacart isn't alone - many companies embarking on the same journey toward cloud data efficiency face the same challenges, and most will follow the same pattern of manual labor and piece-by-piece optimizations bolstered by constant tagging and monitoring. The short-term results are worth it, but these time and effort investments could ultimately prove quite fragile.
At every step of the process, there is room for human error. This is particularly true for the SQL refactoring step, where there are a variety of techniques to employ and no clear definition of "done," only "better." Further, in our team's experience, systems requiring manual effort often encourage less-than-optimal behavior. For example, an analyst may break up a large, inefficient, or expensive query into smaller sub-queries to avoid being tagged as needing a refactor. These pitfalls can lead to inconsistent (and potentially unsustainable) results.
Luckily, there is a faster, cheaper, and more sustainable option - Single Origin. Single Origin automates analyzing, cataloging, and optimizing SQL queries, while providing features like column-level lineage for enhanced observability and governance.
If you lack the data platform resources of a company like Instacart or want an automated approach to tracking and optimizing your queries while aligning your data operations for the long-term, look no further than Single Origin.
Automated Query Insights and Optimizations in Single Origin
With Single Origin, you can organize and optimize thousands of queries in minutes. First, bring in a set of queries you'd like to organize, optimize, and make shareable across your organization.
Then, perform a Query Audit on the collection, an operation that groups your queries based on their underlying logic. Query Audits reveal insights into cost, performance, and usage patterns. In minutes, you can bypass dozens of hours of tagging, fingerprinting, and analysis.
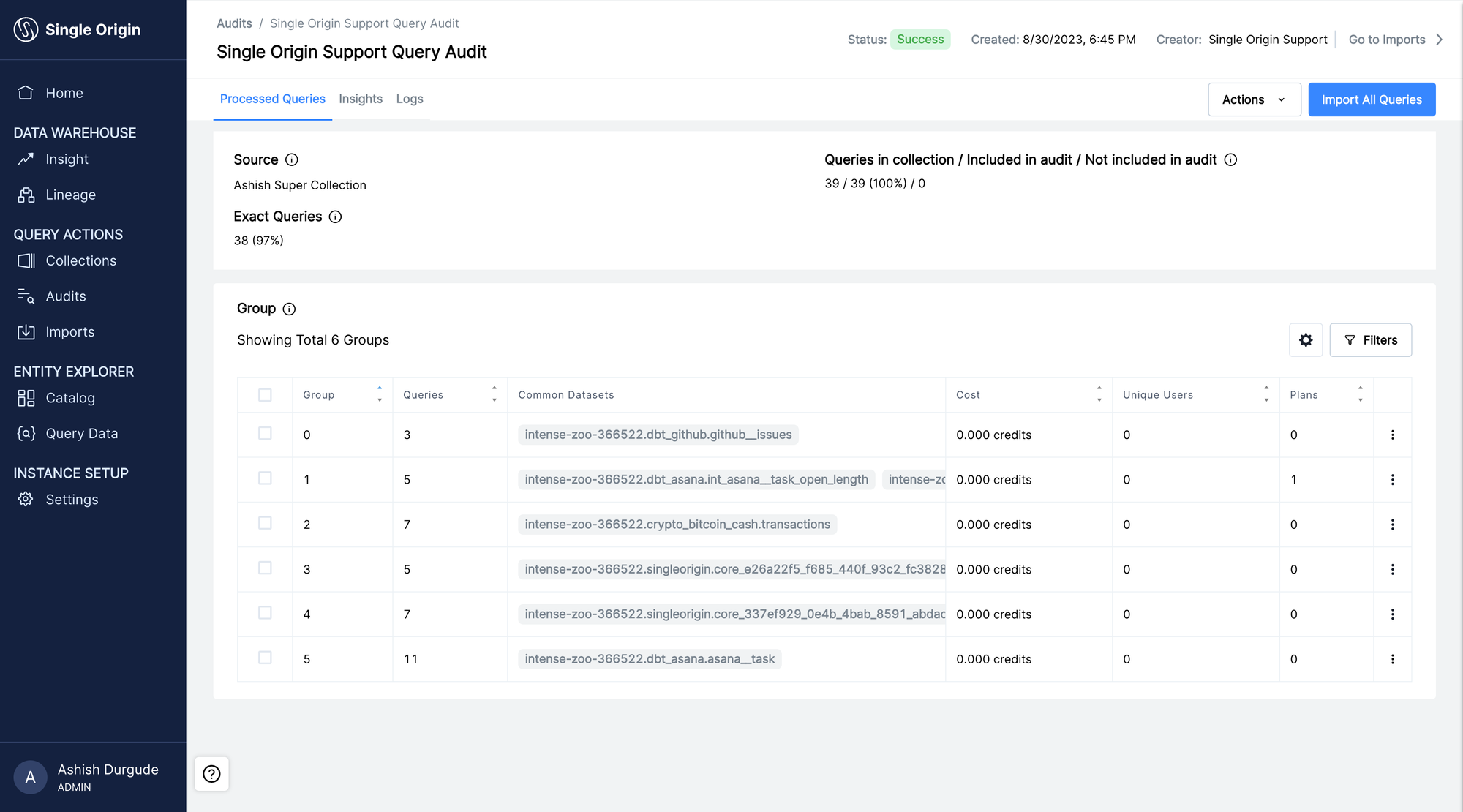
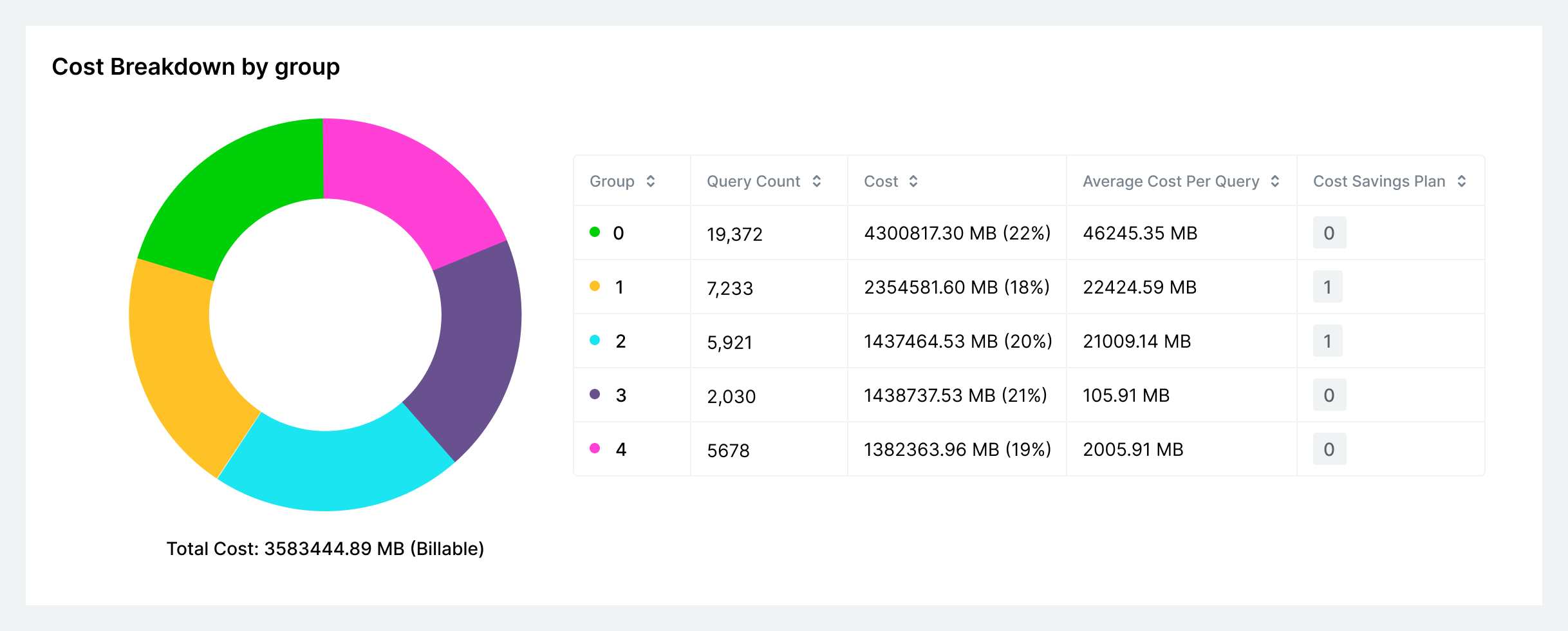
The expensive and redundant queries identified in your query audit make a great place to start optimizing. Unlike the traditional approach to improving query performance, optimizing your queries in Single Origin is programmatic and automated. Instead of chasing down granular query details and rewriting them by hand, you can create a Core Dataset, an optimized SQL query that extracts the common computation logic from your group of queries. Single Origin then serves your existing queries with this hyper-efficient dataset and can rewrite new incoming queries to utilize the common dataset on-the-fly.
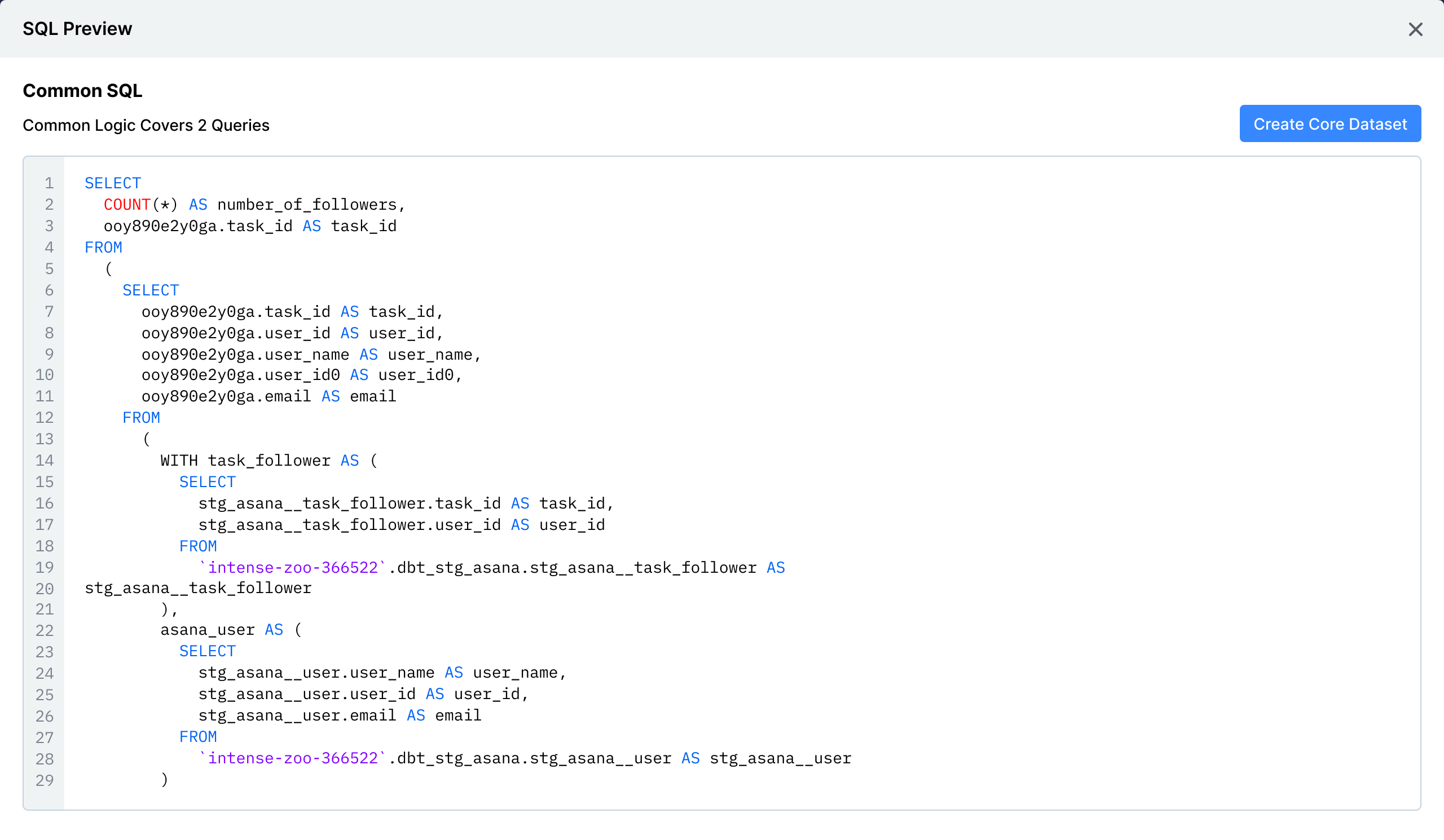
And just like that, we've achieved similar levels of observability and optimization with a few clicks. No manual query tagging, no dbt packages, no sophisticated query fingerprinting, and no DRIs hunting down optimizations one query at a time. All your queries are analyzed and optimized in under 10 minutes.
One Step Further - Cataloging and Sharing Metrics and Views
Single Origin doesn't stop there. In addition to analyzing and optimizing your SQL queries, Single Origin deconstructs them into consumable, shareable metrics and views. This provides a single source of truth for your data definitions, unlocking collaboration and ensuring consistent reporting across your organization.
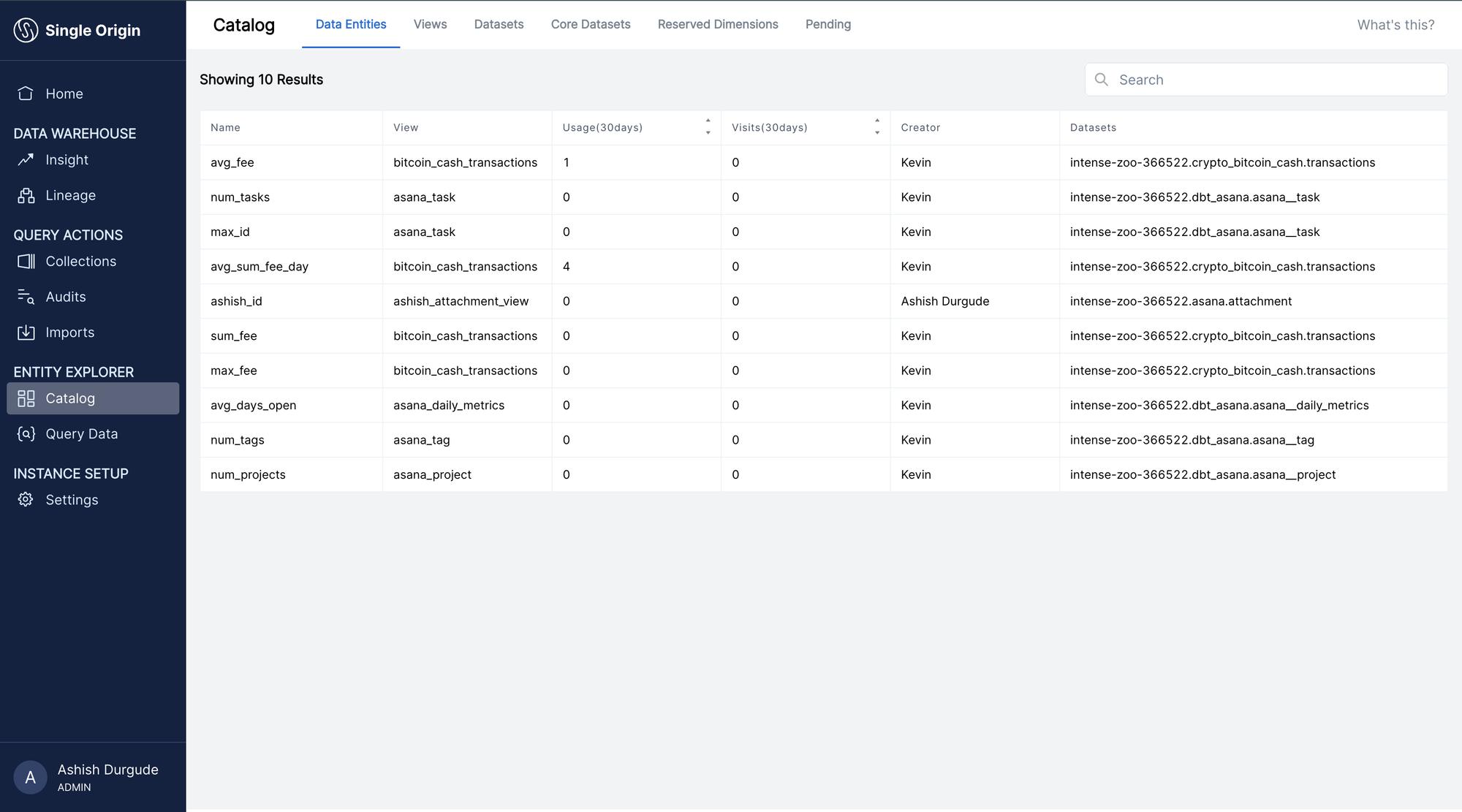
All your metrics, views, and their associated tables also come with explorable column-level lineage, which can be used to enforce access policies and prevent breaking changes from making it to production.
In our benchmarks, Single Origin reduced query costs by up to 90% while improving performance on the same scale. Because Single Origin's approach to query organization and optimization is programmatic, users can expect reliable, consistent, and sustainable improvements to their query layer with minimal effort.
Single Origin isn't just a tool - it's a transformative approach to managing your SQL. By automating query-level observability and optimizations, companies benefit from reduced costs, enhanced performance, and long-term, sustainable data efficiency.
Key Takeaways
- Traditional query optimization strategies are resource-intensive, requiring monitoring, analysis, and additional metadata to identify potential areas of improvement, followed by manual SQL rewrites on a query by query basis.
- While effective in the short-term, these strategies suffer from a lack of automation. This decreases the velocity of data operations and requires significant investment and buy-in from across your organization.
- Single Origin can replicate what took Instacart months in a matter of minutes. It offers a holistic view of your data ecosystem, revealing inefficiencies and delivering insights with no tedious manual labor required.
To begin your journey towards cloud data efficiency, reach out to support@singleorigin.tech to get started. In the meantime, may all your queries be performant and cost-effective.