Single Origin: ready to serve enterprises!
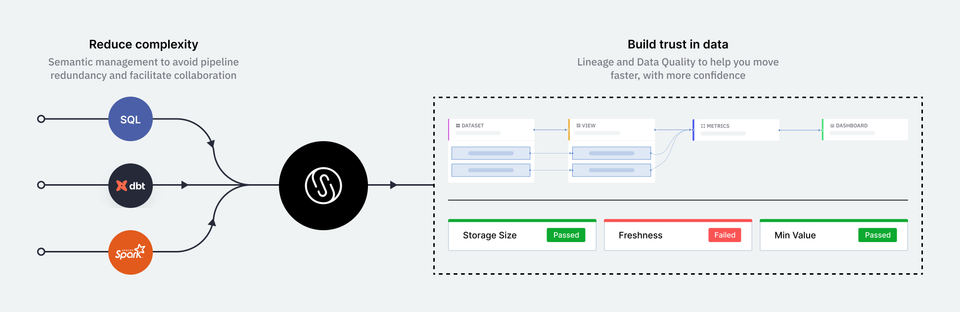
At Single Origin, we aim to empower companies to organize their data, scale effortlessly, and collaborate efficiently. With the Modern Data Stack, as you grow you may realize:
- There could be duplication in your data pipelines, increasing cost and complexity, but you are not sure where.
- It is hard to understand data flow for compliance and observability, and searching for the data you care about is difficult.
- Onboarding users to your data stack is slow, and maintaining structure is complicated.
If you have ever struggled with the above, then we can help!
Getting Started in Single Origin

Once you have an instance, you will build a collection of data entities, dimensions, and views by importing SQL queries. We parse each import using a standard definition model.
We make it easy to import from either Google BigQuery or Snowflake:
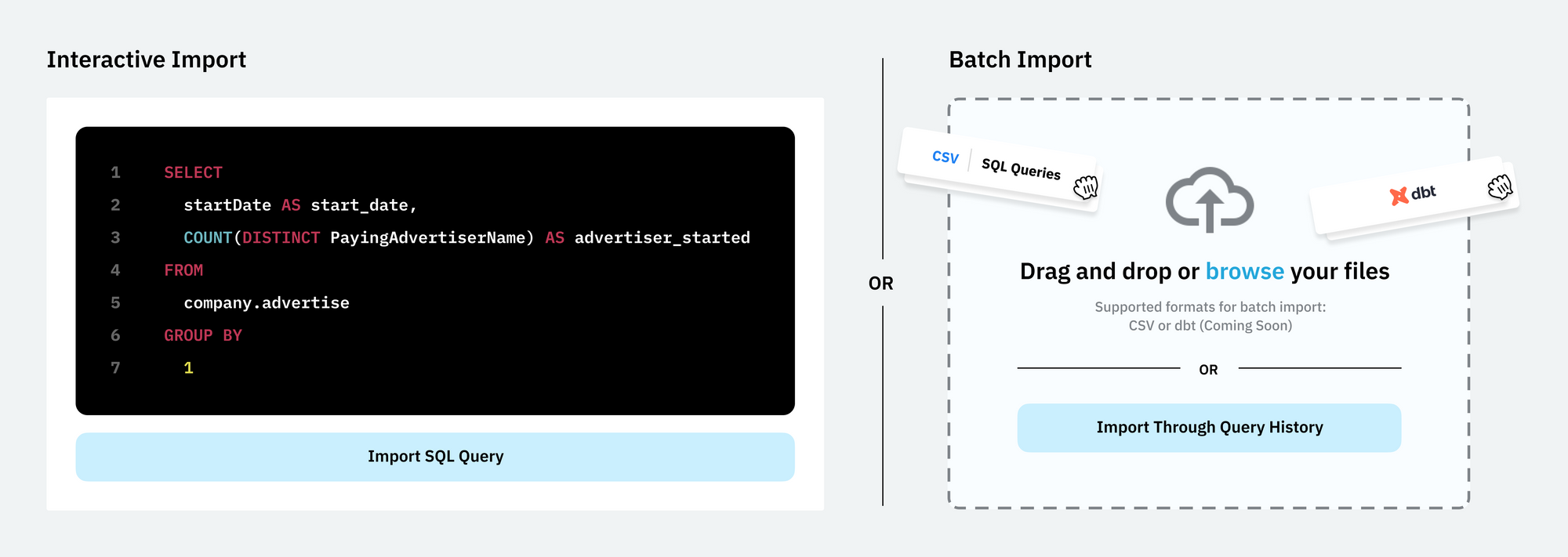
- Query audit. You can run a query audit to understand redundancies in a set of queries. We parse the queries and highlight consolidation opportunities. You can start an import with a single click when an audit is complete.
- Batch import. You can also import a set of queries. We parse the queries, extract entities, and add them to your collection.
- Interactive import. You can import a single query with a guided flow. You can validate the quality of upstream data and then generate a draft to review with others.
Every import and audit includes algorithmic validation to guarantee the uniqueness of entities, minimizing confusion around what a metric or feature means. You can build your collection in a UI - you neither need to know Git nor figure out how to structure your collection.
Reining in Complexity with Single Origin
By importing important queries (e.g., data pipelines) into Single Origin, you are on your way to simplifying the management of your data stack:
- Scale easily. Algorithmic deduping minimizes redundancies so that you can scale to millions of searchable, annotated, and unique definitions. You will never need to rebuild your collection.
- Understand data flows. Fine-grained lineage helps you track the spread of data, debug issues, and gauge the quality of sources.
- Generate insights. You can confidently query your data in the app or via API without writing any SQL. Access is consistent with the upstream data source, so you spend less time managing permissions across tools.
You can build your collection and query your metrics and features in a few minutes. Contact us to see about getting started today!
For more information, check out our documentation (including connecting, auditing, and importing), blog posts about the platform, or explore the app with our public sandbox. You can also watch a 5-minute onboarding video below!

