Throughlines: Tracing Data With Field-level Lineage, Part 1
At Single Origin, we believe that efficient collaboration and reliable insights require standardized definitions. Standardization makes sharing context and getting data operators on the same page easier.
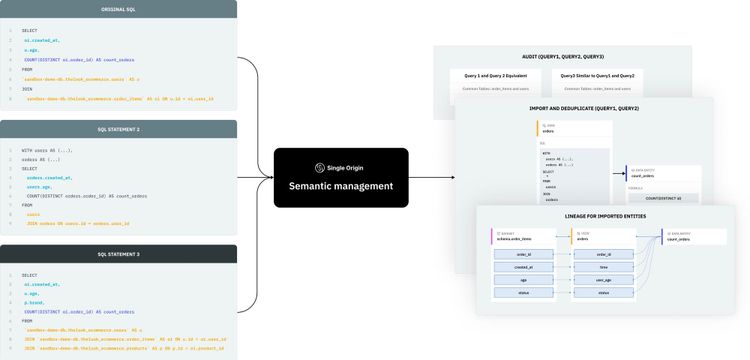
When you import SQL queries into Single Origin, we parse, validate, analyze, and transform your queries into standardized definitions based on the query semantics. We break down queries into sets of data entities, dimensions, and views. We define their relationships below.
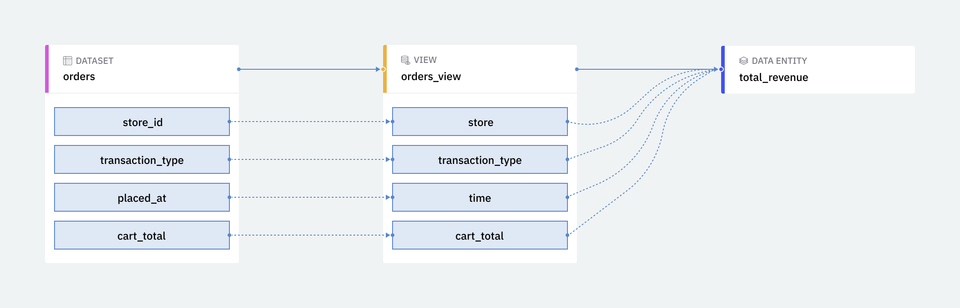
- Data Entities depend on a view.
- Views depend on one or multiple datasets.
- Dimensions are attributes of views used to group or filter data.
- Datasets are tables and columns in your data warehouse.
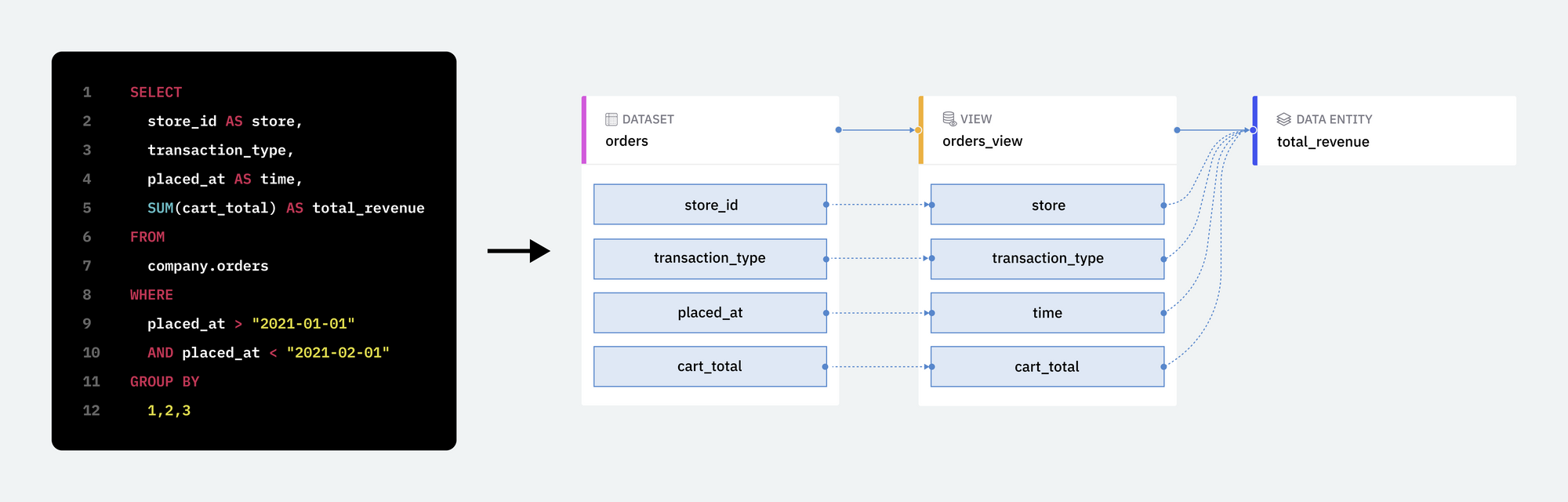
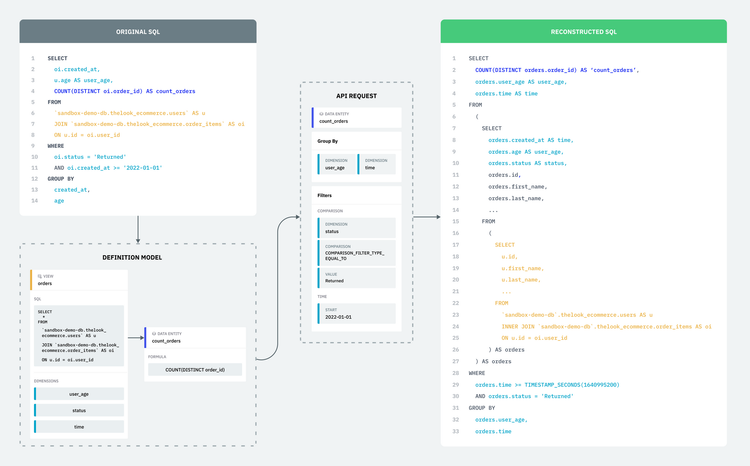
Single Origin derives field-level lineage without additional user input by parsing every imported SQL query. Field-level lineage demonstrates the SQL transformation between the granular relationships across fields (properties of views, data entities, and dimensions) and columns (properties of datasets).
Building the field-level lineage for an entity in Single Origin starts when you import a SQL query.
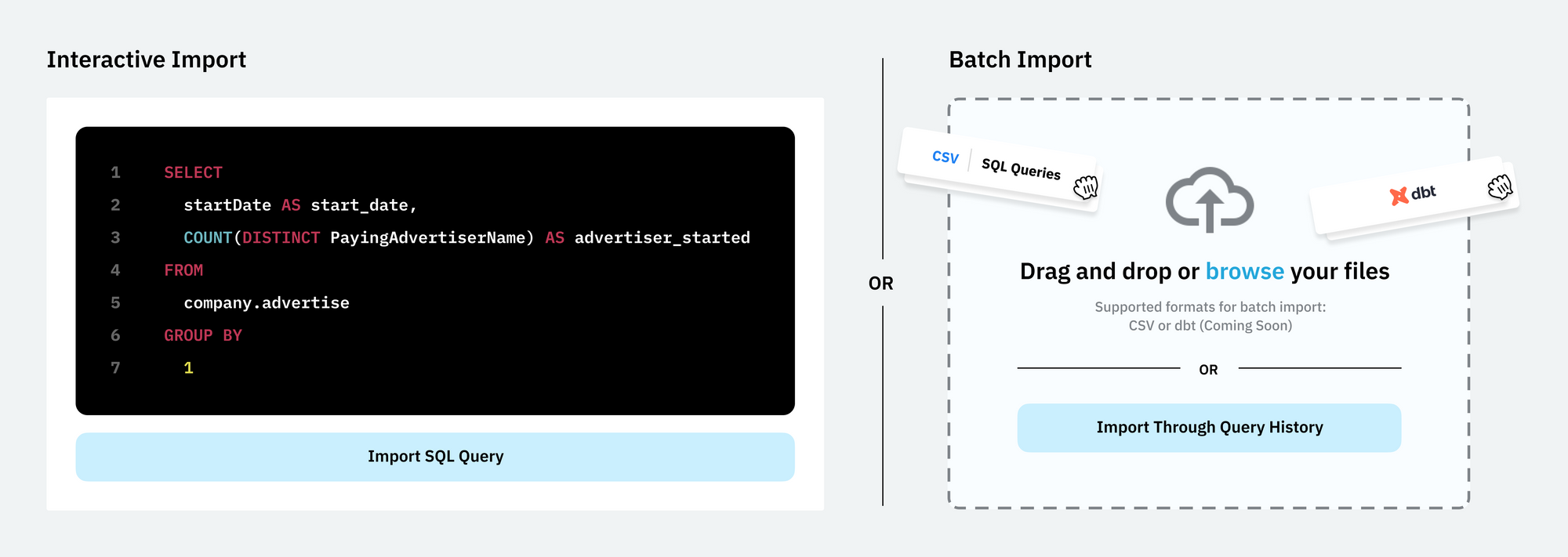
There are multiple ways to import SQL queries:
- Interactive import - use our SQL editor to define data entities.
- Batch import - connect to your query history table in your data warehouse or import by uploading SQL queries in CSV or dbt projects.
The number of datasets under management can increase exponentially as new business requirements arise, more users import data, or when ELT pipelines are used to generate tables and models. Organizations experience data quality degradation, compliance risks, and friction between data producers and consumers as they scale. Using field-level lineage, users can visualize their data flow, allowing them to debug data issues, ensure regulatory compliance, and enhance data observability.
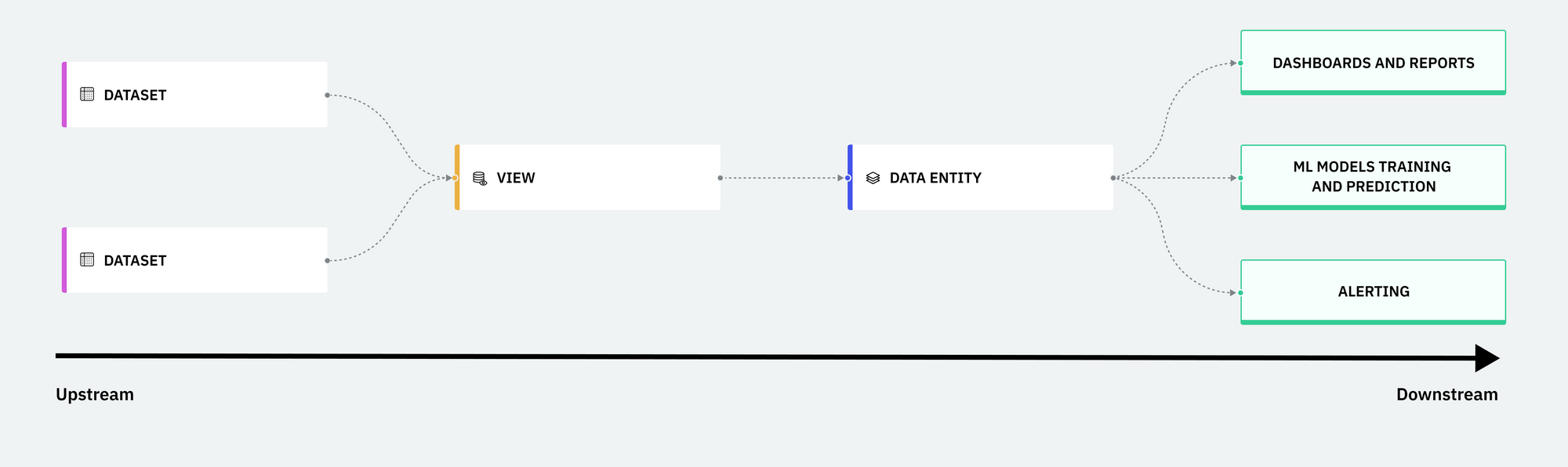
Debugging
Single Origin allows users to find the root cause of their data quality issues by tracing data upstream to its source field. Unlike coarse-grained table-level lineage, field-level lineage provides faster, precise insight into upstream fields. This leads to higher quality data entities for downstream consumers.
Compliance
When using field-level lineage, access permissions are inherited from the data warehouse, which manages and restricts who has access to data entities.
Observability
By combining semantic management with field-level lineage, users can reveal how updating pipeline logic will impact downstream consumers. When standard definitions are changed, data entities may be affected downstream. Backward incompatible changes are detected automatically.
Conclusion
To build field-level lineage, all we require is a set of compiled SQL queries. In the future, we will be able to support field-level lineage for import sources like Airflow pipelines or dbt projects. With Single Origin, the import and lineage-building process are automated. The more SQL queries provided, the more coverage our system can provide to end users.
Single Origin makes it easy to understand how your data flows with field-level lineage. In part 2 of this series, we will provide a technical deep dive into how we built field-level lineage at Single Origin.