Semantic management & data operator efficiency

In the past, we've explored Single Origin's features - how they work and stack up to similar products. Today, we will take a step back to examine some fundamental questions about the semantic management space. What are the core problems facing data teams today? What features should you look for in a semantic management platform? And how can semantic management optimize and streamline your data assets?
Current State of the Data Stack
The current state of modern, data-driven companies is complex. Many companies have thousands of models, often leading to complicated Directed Acyclic Graphs (DAGs) that are difficult to understand - let alone modify. While various teams working on different projects may have similar goals, it is infeasible for them to dig through thousands of models to reuse or change what already exists. Over time, the costs add up - onboarding is more expensive, and teams become immobilized by complexity. Meanwhile, data cloud costs continue to grow from untamed redundancy.
In addition, many companies struggle with governance and quality in their SQL. In today's data stack, there are many places where users execute queries, meaning many surfaces that require access control. These tools are designed for users with varying experience levels, making it hard to maintain consistency and quality across the SQL being generated and run.
So, these are the problems data teams face today. The data sprawl is real, making it hard for companies to achieve self-serve data. Users need to know:
- What data assets exist, what each means, and how they differ
- Where to make changes
- What is being queried
- Who has access
- How to share knowledge
But they aren't equipped with the tools to navigate this complexity.

Single Origin is the Way
Single Origin is the tool for managing the complexity of your data assets. By automating the reuse of existing data assets, Single Origin creates a streamlined DAG that minimizes complexity. This automation is made possible by Single Origin's ability to analyze compiled SQL across different clouds, identifying areas where data can be streamlined and optimized. Instead of sifting through thousands of daily queries, users can rely on Single Origin to do the heavy lifting.
Our case studies have highlighted opportunities to reduce overhead and query costs by 50-90%. Additionally, users can generate and explore the field-level lineage of their queries in our UI without additional tools or setup.
This is all achieved through Single Origin's SQL parser, which uses a standardized definition model to map your SQL metrics. Users can then regulate access at the metric level, not just the dataset level. This ensures internal data remains safe and secure. Single Origin automates, synchronizes, and catalogs these metrics for discoverability and collaboration. It's all accessible via a single link.

Conclusion
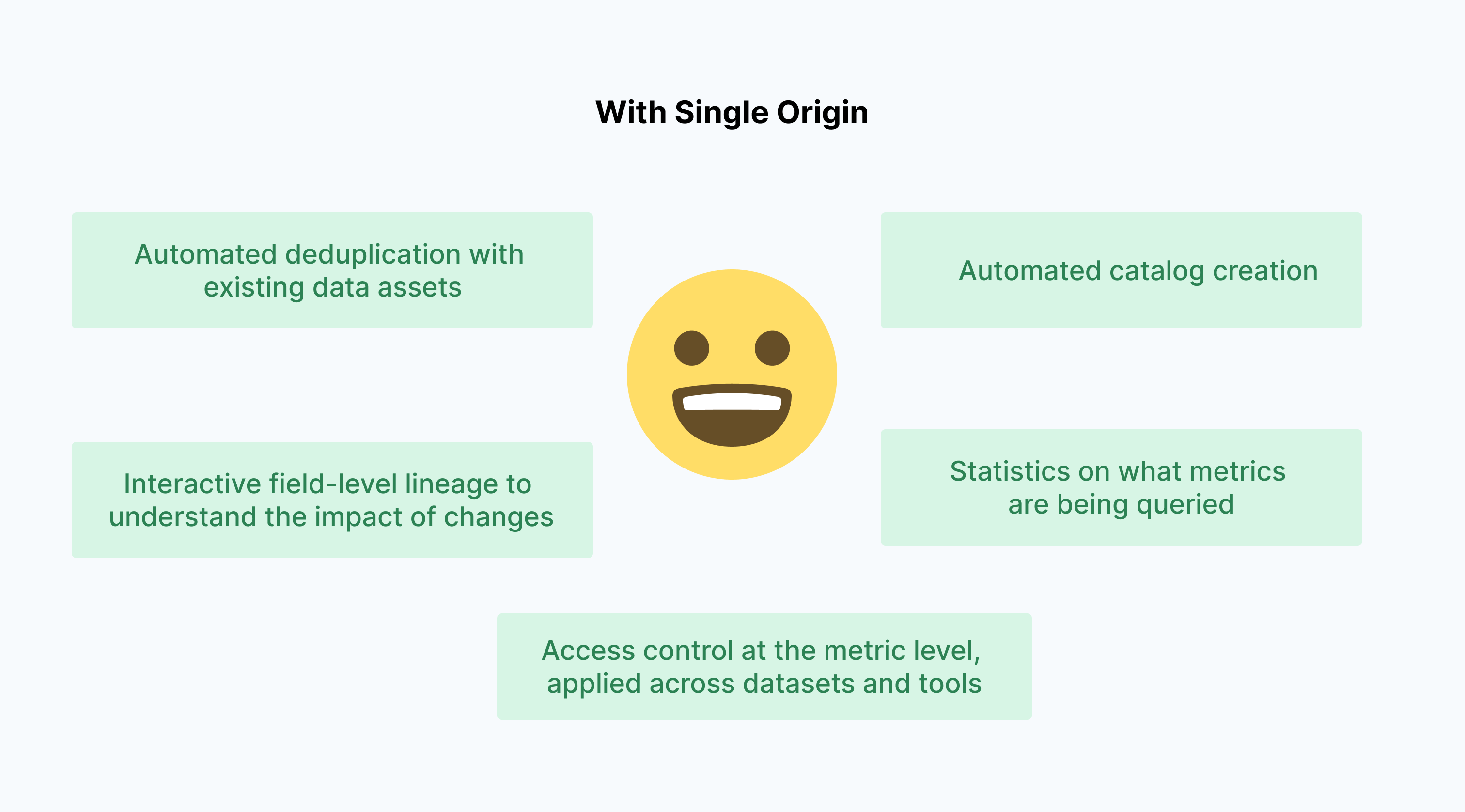
In conclusion, by using Single Origin, users can enjoy a more streamlined, efficient, secure, and collaborative data management process:
- Automated deduplication with existing data assets
- Interactive field-level lineage to understand the impact of changes
- Access control at the metric level, applied across datasets and tools
- Statistics on what metrics are being queried
- Automated catalog creation
For more information on how Single Origin can make managing your data assets easier, check out our website and subscribe to this blog. Until next time!
