Race to the finish line(age): 3 Field-Level Lineage Solutions

Field-level lineage, or the ability to trace the origin and flow of data within individual fields of a database table, is no longer a nice-to-have feature for organizations with data-intensive workloads. It’s a must have.
Data-intensive organizations need to track where data in a field originates from, how it’s transformed, and how it’s used in their data systems, BI tools, and ML models. To give an example, data operators may need to track down where a field like user_email is consumed for GDPR compliance purposes.
Today, this is a difficult task for most businesses. However, a new crop of tools and techniques are emerging to deliver this essential functionality.
Many lineage solutions are still in their infancy. These tools usually derive lineage by parsing raw SQL and/or collecting metadata provided by your data systems. While the techniques to derive lineage may be similar across tools, functionality can vary in important ways. For example:
- Support for different technologies (different SQL dialects and data stores)
- Support for lineage visualization to debug data issues, ensure regulatory compliance and enhance data observability.
- Support for both dataset and field-level lineage granularity, where dataset-level lineage is the lineage between datasets, and field-level lineage is between fields (columns in a table, for example).
Before we begin, a brief overview of the contestants:
Google Cloud is a suite of cloud-based solutions. Its data warehouse, BigQuery, does not officially support field-level lineage. However, a team of engineers at Google Cloud has come up with a DIY approach to loading and parsing SQL to create field-level lineage. Please note: this is the closest solution to field-level lineage offered by Google Cloud. We will use it as a baseline to compare against the other two technologies.
OpenLineage is an open standard for collecting lineage data. It comes with a limited storage solution on its own - a metadata, repository reference implementation known as Marquez. However, it is most often integrated with tools like Airflow and Spark to perform lineage collection. When integrated into these systems, OpenLineage can collect information about Airflow or Spark runs and produce lineage for associated queries.
Single Origin is an all-in-one semantic management solution to organize, trace, and govern your SQL queries with ease. The system leverages advanced SQL parsers to break down queries into a common and reusable definition model. This parsing enables numerous features, including constructing field-level lineage. You can interact with your lineage via a set of APIs and a comprehensive UI.
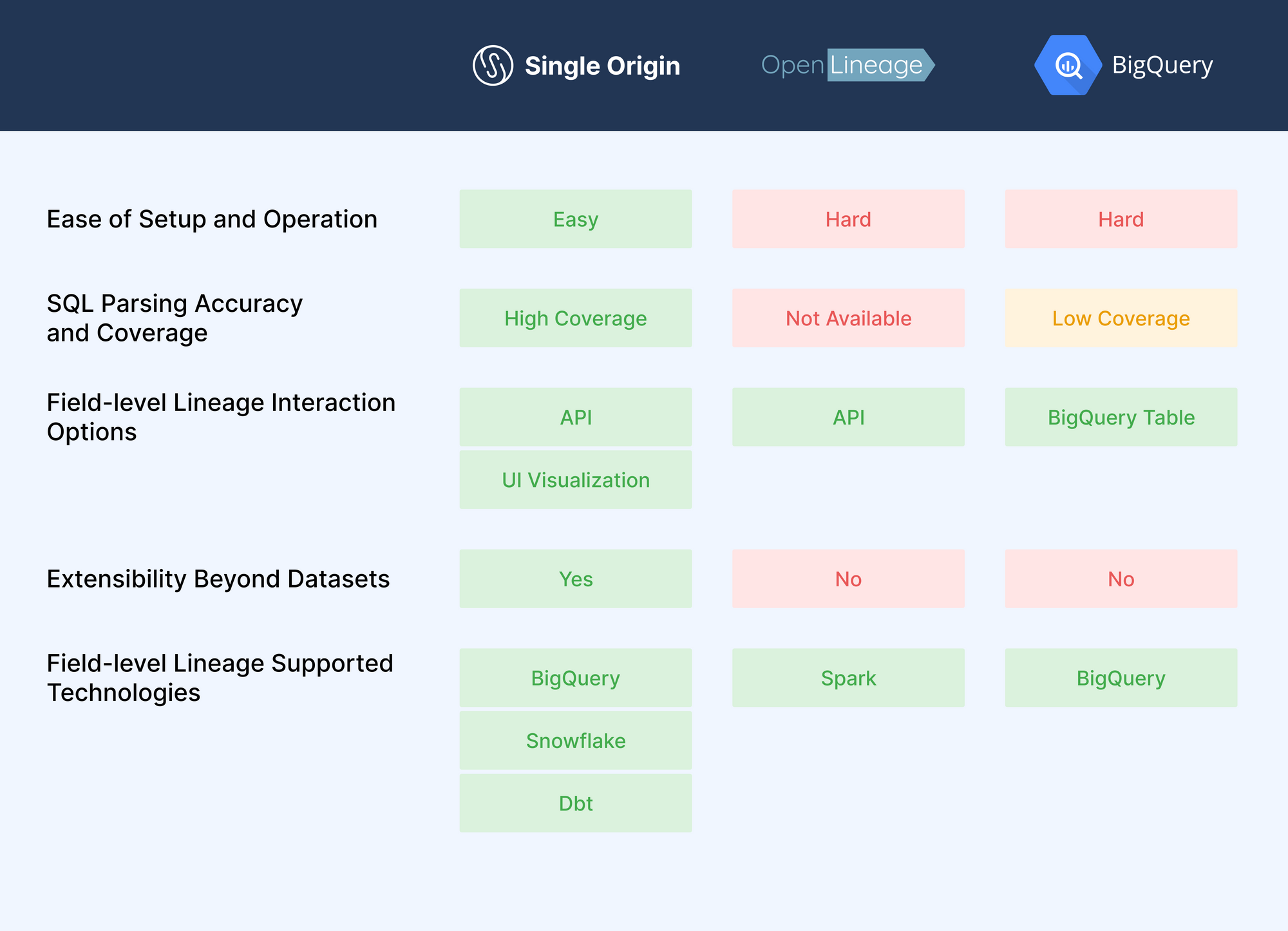
We will compare Google Cloud, OpenLineage, and Single Origin across five categories:
- Ease of setup and operation
- Accuracy and coverage of SQL parsing
- Lineage visualization and API support
- Extensibility beyond datasets
- Number of supported technologies
Let the battle royale begin! 🤼
Category 1: Ease of Setup and Operation
How easy is it to set up? What are the prerequisites?
Google Cloud:
The main components in the architecture of the tutorial laid out by the cloud engineering team at Google look something like this: BigQuery acts as the data warehouse and schema provider, and BigQuery audit logs are used as operation logs. Messages in the logs contain resource information, like dataset names and executed SQL queries. ZetaSQL is used as the grammar and engine.
This is not a particularly friendly process. It’s more of a novelty for the curious developer than a full-fledged solution. The extraction pipeline must be set up to pub/sub audit logs emitted from BigQuery, then send them to dataflow for processing with ZetaSQL, and lastly, dump the processed data back into a BigQuery dataset.
This will deliver you lineage. What you can do with it is limited, but we’ll cover that in another section.
This is not a trivial amount of work and would require maintenance from developers. Not the most robust option, nor the most simple. But hey, it’s an option.
OpenLineage:
OpenLineage requires considerable setup, deployment and maintenance. First, you need to set up a backend API service that’s compatible with OpenLineage specs. You also have to implement the necessary middleware for Spark and Airflow. When setting up the integration, you are also required to add OpenLineage artifacts into your Spark or Airflow deployments, then update the existing pipelines with an OpenLineage configuration to ensure it goes to a backend. If you are already working with Spark and Airflow, this process is relatively simple to start emitting the lineage information, but you still have to set up a backend to host and explore them.
Single Origin:
To get field-level lineage across various datasets and data sources, you can complete the setup through a user-friendly UI. First, you need to connect to your data warehouse. Then, select the source of your query metadata. This can be directly from your data warehouse or in a CSV file. Then all you have to do is click import. It’s that simple. This means folks at all technical levels can both set up and operate Single Origin.
Category 2: Accuracy and Coverage of SQL parsing
What SQL dialects are covered? How accurate is the lineage derived from the SQL parsing?
Google Cloud:
The suggested architecture from Google uses ZetaSQL to parse BigQuery SQL statements. This comes with some major drawbacks: ZetaSQL does not support DDL statements (commonly found in ETL tools like dbt).
Here are a few examples of unsupported queries:
- CREATE TABLE target AS SELECT * FROM source
- INSERT INTO target SELECT name FROM source
- Deriving lineage from CTE is not supported, for example:
- WITH target AS (SELECT name FROM source) SELECT * from target
ZetaSQL only supports LOAD, QUERY and COPY jobs. You also must specify a fully qualified name when you make a query.
Due to these limitations, many SQL statements will not be parseable, making field-level lineage difficult or impossible to discern for queries like those above.
OpenLineage:
With OpenLineage, field-level lineage is only possible when working with SparkSQL and Spark. If you’re not using Spark, you will have to migrate to SparkSQL for field-level lineage to be captured for your system.
OpenLineage’s support for field-level lineage is concentrated on SparkSQL because the logical plans generated for a Spark job already contain field-level information. When OpenLineage is used in conjunction with Airflow, only dataset-level lineage is supported, as OpenLineage does not yet have a robust SQL parser to derive field-level lineage from raw SQL.
Single Origin:
Single Origin’s core offering is its SQL parser and definition model, which can be extended to process any SQL statement without the above limitations. For more details on how Single Origin achieves this, check out our earlier blog: Throughlines: Tracing Data With Field-level Lineage, Part 2. This means Single Origin is more likely to work with your existing queries. The coverage of statements that can be parsed is also higher, which leads to a more complete view of your lineage.
Category 3: API and Lineage Visualization Support
How can you interact with the lineage data?
Google Cloud:
Due to the unsupported nature of the approach provided by Google’s team, there are no APIs and no UI to explore field-level lineage. You must query from a BigQuery dataset containing this information in a JSON-string format. There is a UI to explore dataset-level lineage, but it is only available in preview mode.
OpenLineage:
A REST API to fetch Spark field-level lineage information is available if you set up an OpenLineage backend (Marquez). However, there is no UI support for field-level lineage visualization.
Single Origin:
You can interface with field-level lineage through a set of APIs or by visualizing it in Single Origin’s UI. APIs are useful for users that need lineage data to perform other actions such as compliance and quality checks. The UI allows technical and non-technical users to explore relationships of fields across many views and datasets.
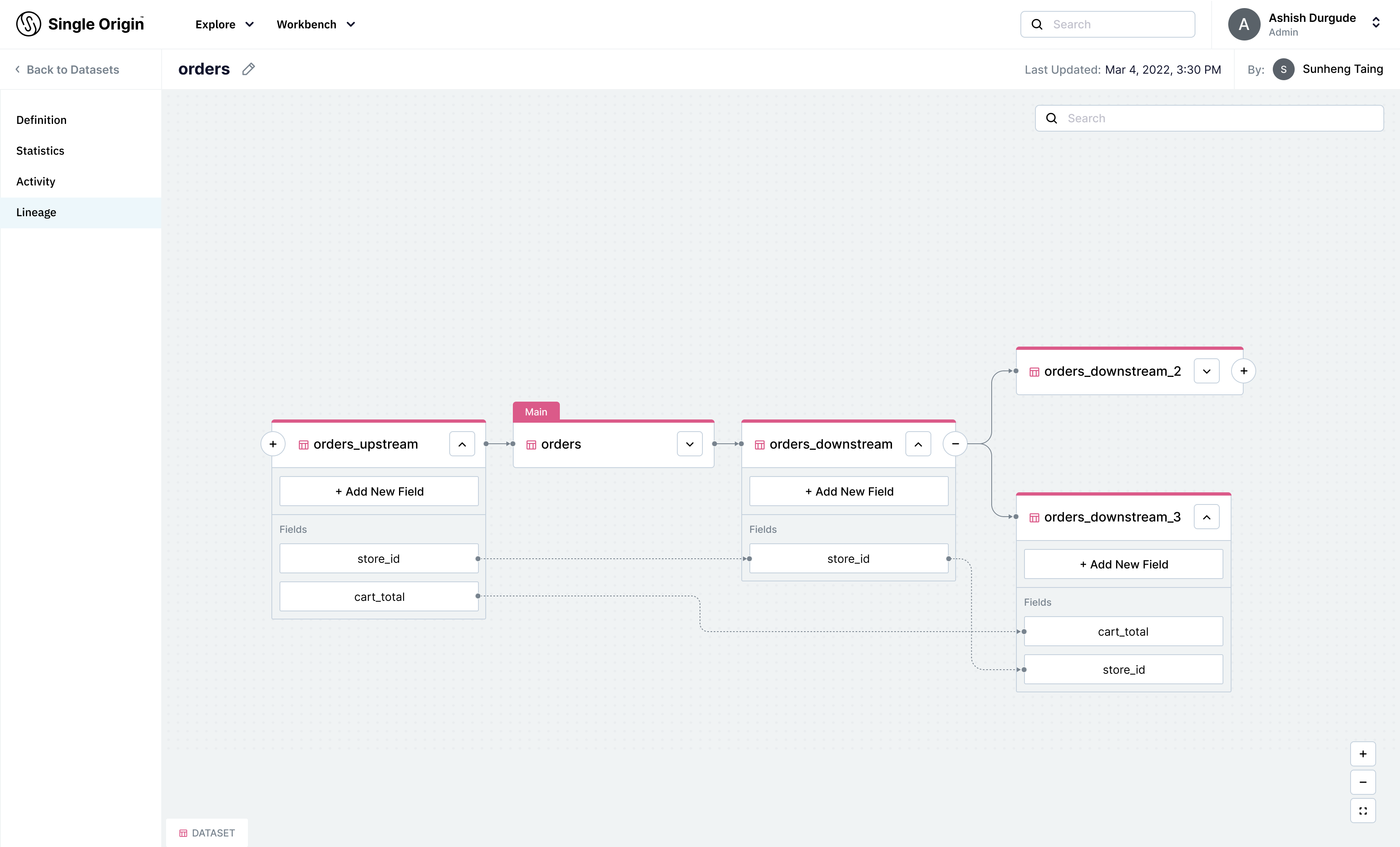
Category 4: Extensibility Beyond Datasets
What are other entity types can you trace in your lineage graph?
Google Cloud:
The current offering of lineage is exclusively tied to BigQuery. You can only see BigQuery datasets and BigQuery job information. There are no steps provided by Google to support ingesting other entity types into the graph.
OpenLineage:
Similar to BigQuery, OpenLineage focuses on datasets, jobs, and runs. However, a considerable amount of work is necessary to complete a lineage graph with various types of upstream and downstream concerns. The OpenLineage API needs to be extended beyond existing supported types in order to produce lineage across different technologies.
Single Origin:
Single Origin’s field-level lineage contains datasets as well, but the implementation is extensible to any system/tool that calls your Single Origin entities (for example, a BI tool or models). This gives you a global view of everything around your data. Your lineage graph may start with Datasets and the operations around it, but it does not end there. Downstream consumers such as metrics, models, and dashboards shouldn’t be ignored. Single Origin offers the most extensible lineage solution.
Category 5: Number of supported technologies
Does it fit into your company’s data stack?
Google Cloud:
Like most cloud vendors, Google focuses on its own product offering. Google will likely only support BigQuery lineage in the future.
OpenLineage:
Spark is the only technology that supports Field-level lineage with OpenLineage, though integrations to derive field-level lineage with Airflow are underway.
Single Origin:
If the underlying technology is SQL (like Spark SQL, for example), expanding the platform is straightforward. This gives Single Origin the flexibility to support a wide range of potential technologies in any organization’s tech stack. Currently, Single Origin can derive field-level lineage from any workload in your BigQuery or Snowflake data warehouse, regardless of your data stack. Custom solutions are available for new customers, so please reach out to our team to discuss your needs.
Conclusion
Not every lineage solution is created equally. If you are in the Spark ecosystem, give OpenLineage a try. If lineage is a novelty more than an important piece of your data solutions, the BigQuery hacking may do the trick. If you’re looking for a more comprehensive lineage solution, spanning data stores and full field-level lineage out of the box, give Single Origin a try.
For more information on Single Origin, check out our website. For more articles, subscribe to our blog.
Until next time!