Understand and Simplify Data Complexity II: Drive Compute Efficiency By Optimizing Query Redundancies

For data engineering teams at large enterprises, cost-efficiency is top of mind. These organizations are laser focused on paying less to deliver the same insights, or on flattening the cost curve even as data grows exponentially.
One significant hurdle to efficiency is that users tend to write jobs and queries that do redundant things. This is inevitable when there are hundreds (or even thousands) of people working with the data every day! But how big of a problem is it really?
It’s actually hard to quantify:
- How much redundancy exists across queries that run every day
- How much can be saved by consolidating redundant queries
- How much can be saved by improving table partitioning and sorting to better serve actual query traffic
- And, how spread out these savings are - in other words, can we capture 80% of the savings by optimizing the top 5 things, or is it more like a thousand paper cuts?
In this post, we dive into why these are difficult questions to answer, and introduce a new offering from Single Origin to tackle this problem: Query Fragments.
Valuable insights are hard to get
Most enterprises have:
- A record of the queries issued each day against a particular data warehouse
- A cost estimate for each query
- And (sometimes) more detailed profiling information on the stages of query execution
But getting quality insights on query redundancy from this starting point is hard for a few reasons.
Many queries are complex
Real-world queries are often hundreds of lines long. This makes it hard to visually inspect the most expensive queries and reason about what they have in common. It can even be onerous just to inspect a single query to figure out what it does!
Queries must be decomposed
To really find redundancies, we need to break down queries into smaller parts. Often, the redundant parts are smaller fragments within complex top-level queries. Here’s an example:

Both queries do a full scan and window function on customer update events, up to some cutoff time. We wouldn’t be able to detect this without breaking the queries down, because the full queries themselves are actually quite different.
Not all redundancies are significant
Finding every possible query snippet that is redundant in a large query workload would create an overwhelming number of matches to look at (not to mention, it would be computationally expensive). To narrow down the field, we want to focus on expensive redundant fragments. This means we need to interpret query profile data (which varies by storage engine) and combine it with the queries themselves so that we can attribute a cost to each fragment of each query.
Fuzzy grouping is important
Finally, when we try to assemble groups of “similar” fragments, we need a more lenient policy than an exact text match, because:
- Queries can vary in superficial ways, like using different aliases, or selecting fields in a different order
- In addition, it is possible for two structurally different queries to express semantically the same thing (e.g. a WHERE NOT IN clause can also be expressed with an ANTI JOIN)
- Finally, even when queries compute different things, they might still perform redundant work! In other words, sometimes we can take two SQL queries and compute a combined result in a single pass more efficiently than running them separately
Our example queries above actually illustrate point 3. The ranking query on the left gets the most recent country for each customer, whereas the one on the right gets the most recent email. We could compute the latest (country, email) in a single pass up front and save the result as a derived table, and then rewrite the two queries to use the derived result. By doing so, we will have consolidated two expensive window functions into one.
Introducing Query Fragments
A query fragment is a piece of a specific query. We highlight fragments that:
- Have a non-trivial cost
- And, are similar to at least one other fragment from another query
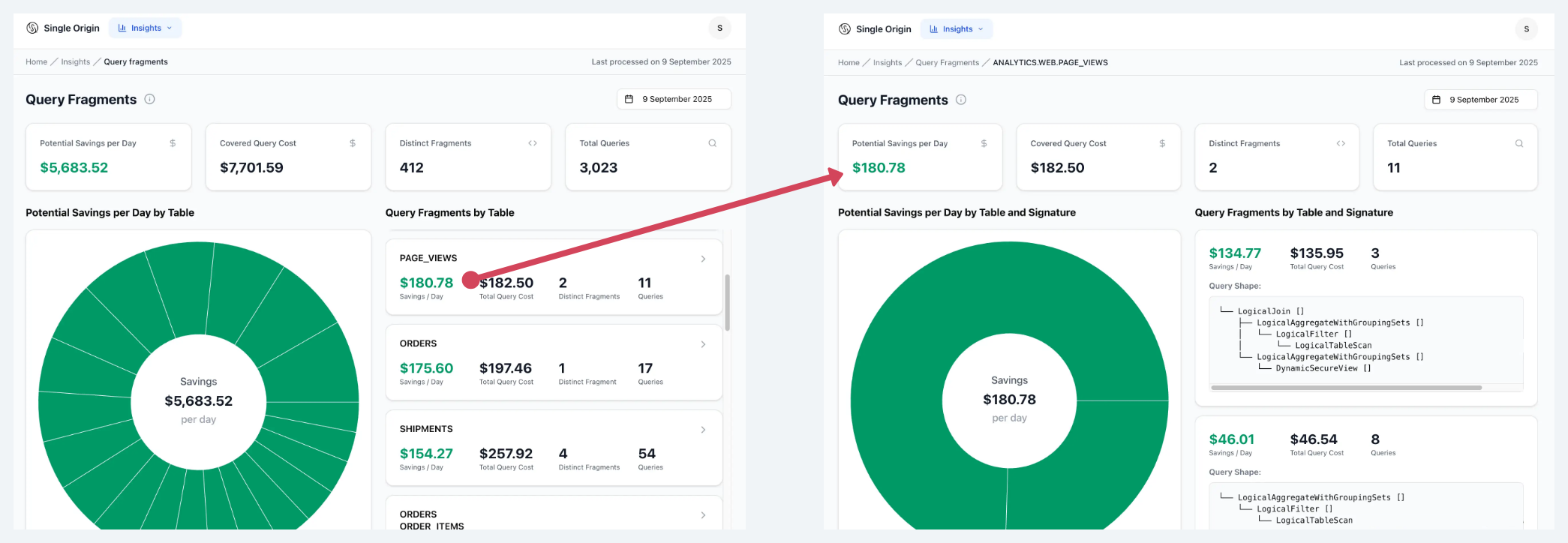
Drill down into potential savings
For each day of query traffic, Single Origin finds query fragments and presents them in a top-down view based on cost. We show:
- A high-level estimate for how much could be saved by optimizing all redundancies across the entire query workload
- A breakdown of this top-level number by table
- Within each table, we show groupings of similar fragments. For each grouping, we show the number of queries it contains, and the potential savings.
- Finally, at the bottom level, we show the individual queries within each group
Generating query fragments
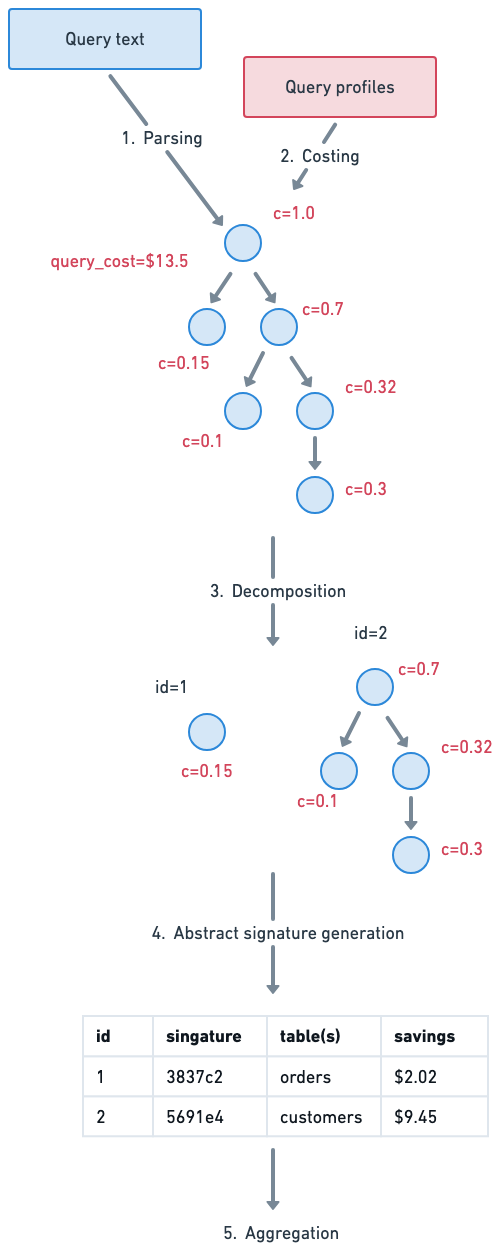
Behind the scenes, query fragments are generated using a five step pipeline:
- Parsing: queries are parsed and converted into a logical plan. This results in a tree structure with nodes for each operation performed on the data, like “scan”, “filter”, and “join”.
- Costing: using per-query profile data, we enrich the tree to add “cost percentage” to each node. This tells us the share of cost that each subtree in the plan consumes.
- Decomposition: we decompose the tree into one or more fragments. Fragments are non-overlapping subtrees of the original plan that are cost-significant. These represent the “pieces” of the query that might be redundant across other queries in the workload.
- Abstract signature generation: each fragment is given a signature that captures what it does at a high level. In other words, we remove certain specifics regarding projection columns, filter conditions, aggregation keys, etc, and then hash the resulting abstract tree. This is how we enable fuzzy grouping—two trees are considered similar if they have the same abstract signature.
- Aggregation: finally, we aggregate on signature to calculate the size and potential savings of each grouping of similar fragments. This data is rolled up in a variety of ways to power the UI drill-down.
Future Applications
We created Query Fragments as a tool to help platform teams find high-impact opportunities to optimize redundancies, looking across all queries. But beyond this, there are other interesting problems that we could tackle given this foundation:
- Help find similar queries during the query authoring process, to nip redundancy at the bud
- Aid in data model evolution by creating tools for table owners to flag queries that still need to be migrated
- Provide auditors with a way to recognize certain anti-patterns in queries that are important to avoid
We plan to keep iterating on Query Fragments to make them more and more useful!