The Limits of LLMs: GPT-4 and SQL

In today’s article, we’ll put GPT-4 through the paces to examine if LLMs are poised to make Single Origin obsolete.
If you’ve been trapped on Everest or stranded on a desert island, you may not have heard about ChatGPT (but congrats on getting out of there alive!). For the rest of us, ChatGPT and large language models have set the world ablaze. AI is the latest craze in Silicon Valley - and for good reason. Advances in machine learning are poised to reshape and revolutionize the way we work and interact with computers.
Many companies are scrambling to find ways to integrate AI into their workflows to harvest productivity gains. Other companies are facing an existential threat to their core business. After seeing some examples of ChatGPT writing SQL, we were excited to get our hands on the latest offerings from OpenAI, GPT-4, and put it to the test doing what we do best - semantic analysis of SQL queries. In our time with ChatGPT, we found it struggled to consistently and accurately analyze or generate SQL like Single Origin. Perhaps most problematically, ChatGPT often provided answers that weaved false-yet-believable answers into the mix. These are particularly difficult to spot, and could lead to poor data quality and decision-making if left unchecked.
We’ll focus on two primary tasks that Single Origin routinely performs - identifying semantic equivalence and generating common computation logic. For the unfamiliar, common computation logic refers to shared computation components, like data loading, table joins, aggregations, etc., across different queries. Extracting this logic from a group of similar queries and refactoring them to rely on the common computation logic can result in significant improvements in cost and performance, much like a materialized view. Semantic equivalence is necessary to perform deduping and recognizing when old data assets can be reused (such as when generating common computation logic).
Semantic Equivalence
In simple use cases, GPT-4 was able to identify semantically equivalent SQL statements. For example, GPT-4 successfully identified the following as equivalent:

However, when faced with a more challenging task, GPT-4 couldn’t keep up. We supplied two SQL queries that are not semantically equivalent - but GPT-4 asserted that the following are equivalent.
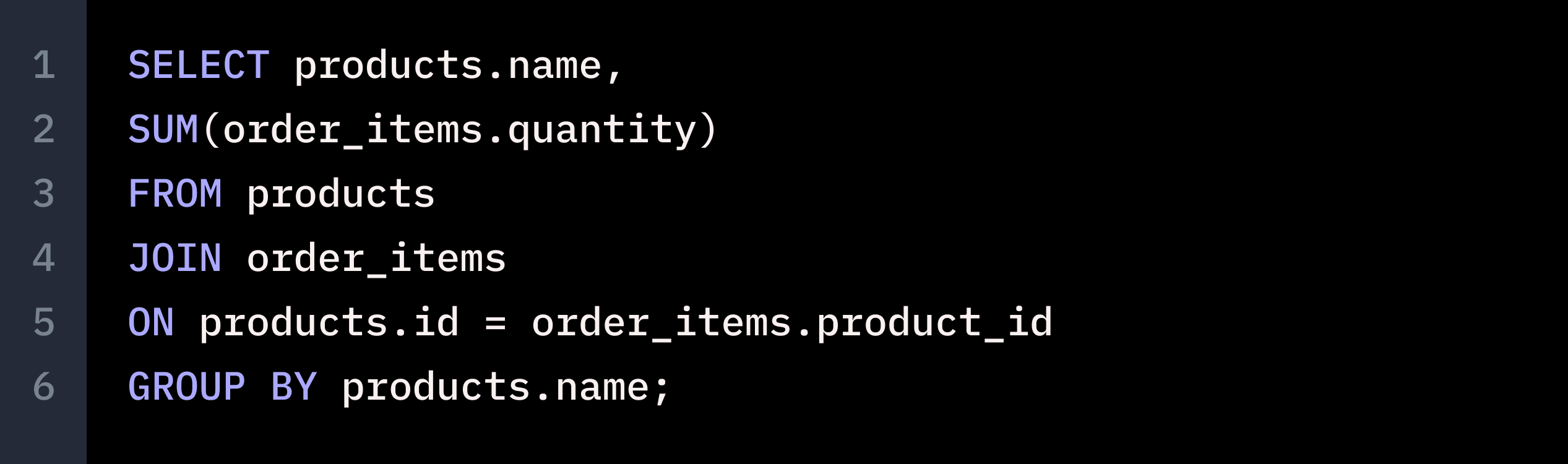
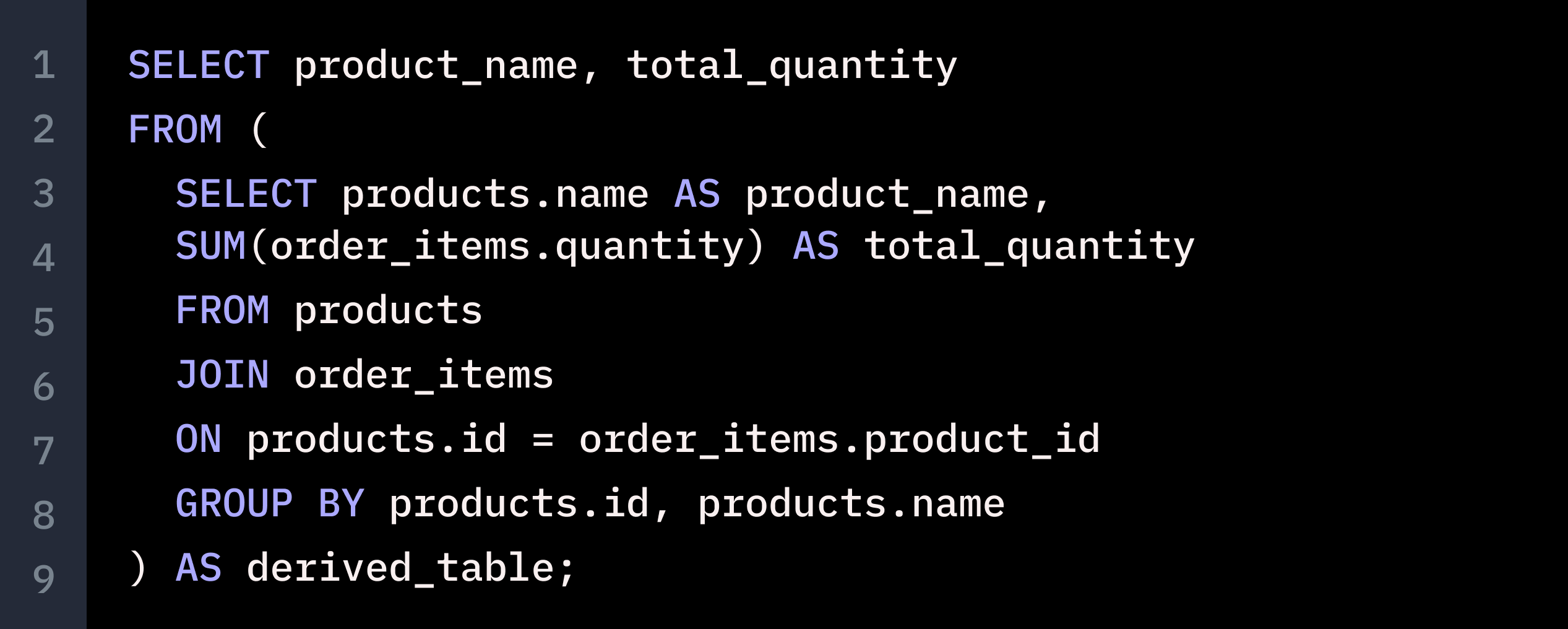
The two SQL statements have different GROUP BYs. Even though the additional GROUP BY column id is not in the selection, it will still generate different results if the id and name are not a 1-1 mapping.
We ran several more examples through ChatGPT, and found that on simple queries, ChatGPT could identify equivalence with reasonable accuracy, but quickly fell apart with longer, more nuanced queries. Here’s an example where ChatGPT failed to identify semantically equivalent queries.

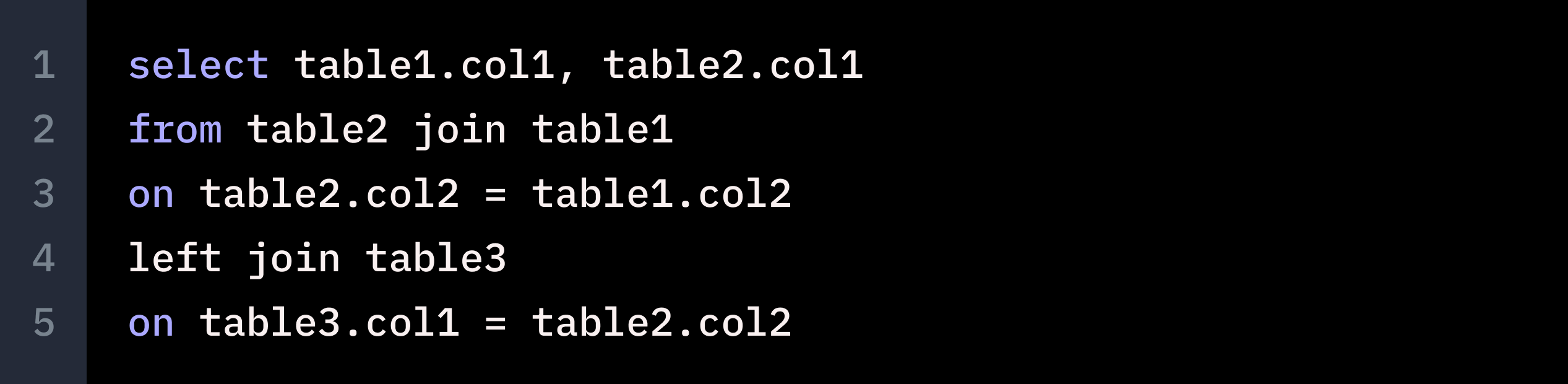
The two queries here are semantically equivalent, even though they have a different inner join order, selection item order and left join condition. The left join condition is semantically equivalent given the inner join condition, which makes the table1.col2 and table2.col2 interchangeable.
Generating Common Computation Logic for a Group of SQL Queries
Lastly, we wanted to test if GPT-4 could handle a core process in the Single Origin platform - taking a large number of queries, grouping them by semantic equivalence and generating common computation logic to serve as a materialized view for the queries. We tried 100 queries, but ChatGPT couldn’t handle it. We paired it down to 10, but the issues persisted. We finally got a response for 3 queries. ChatGPT may have been able to take the queries as input, and even recognize that a common computation table could be generated to serve the three queries, but it was unable to generate a correct common computation table. Here’s what we passed in:
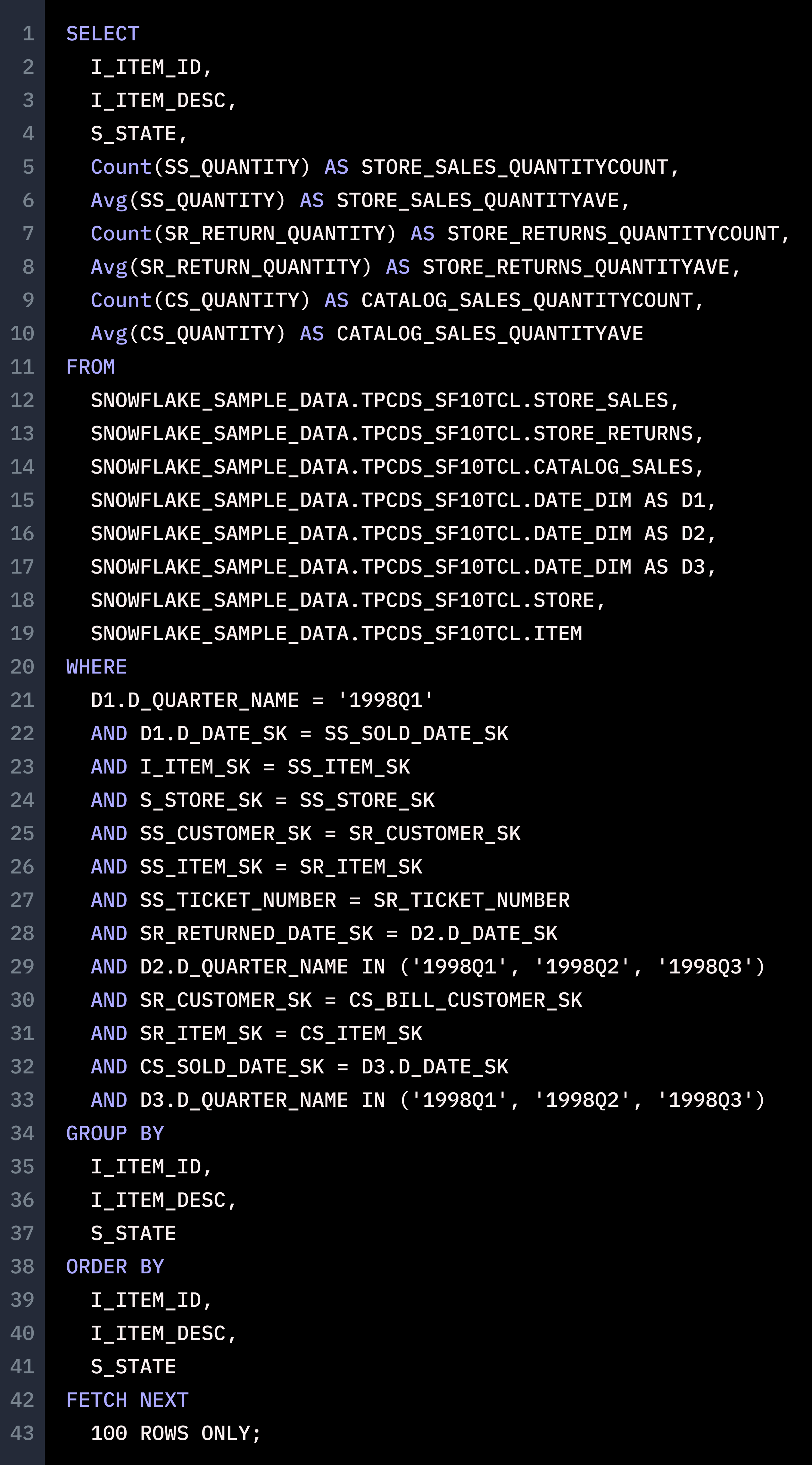
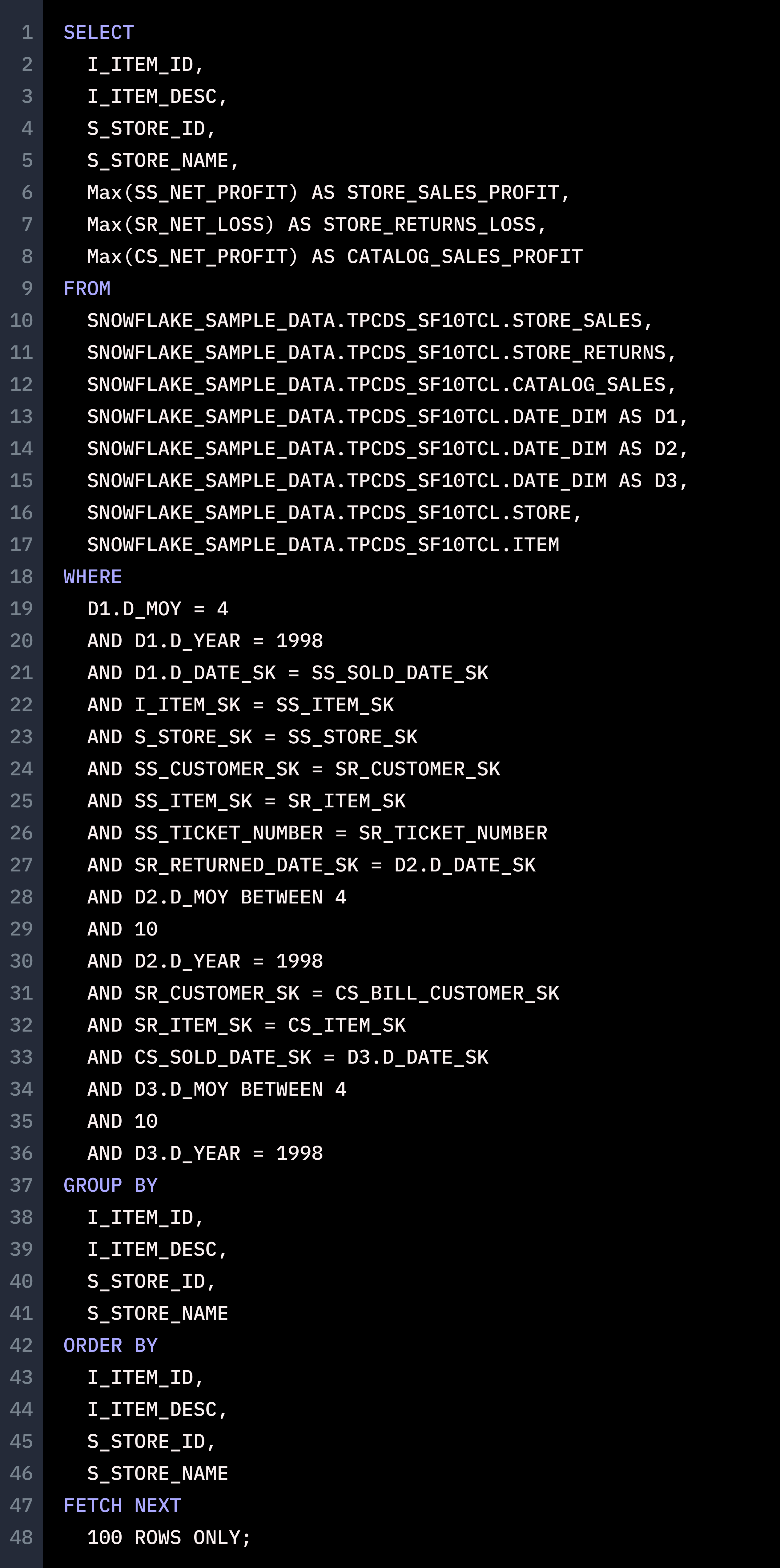
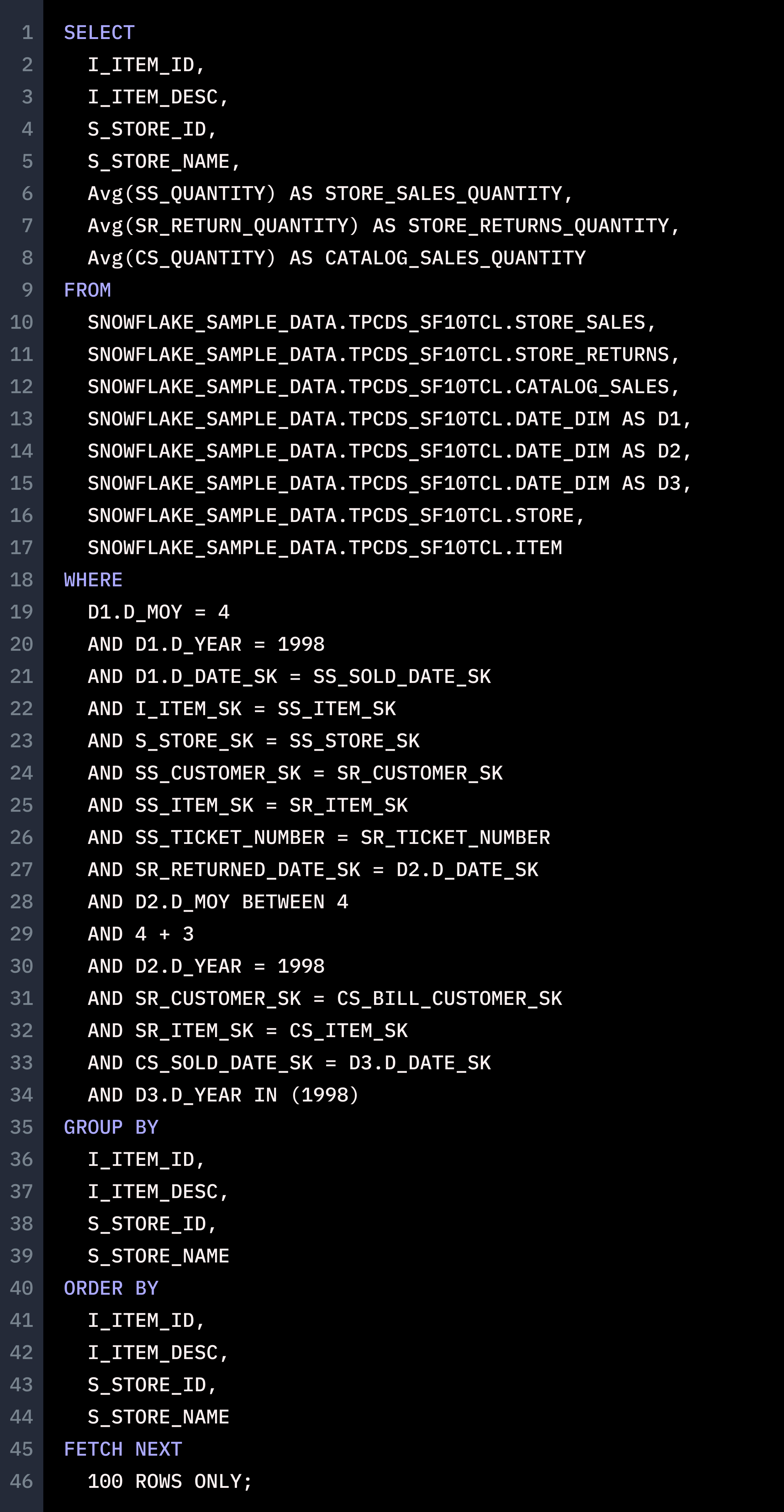
And this was the common computation logic ChatGPT supplied us:
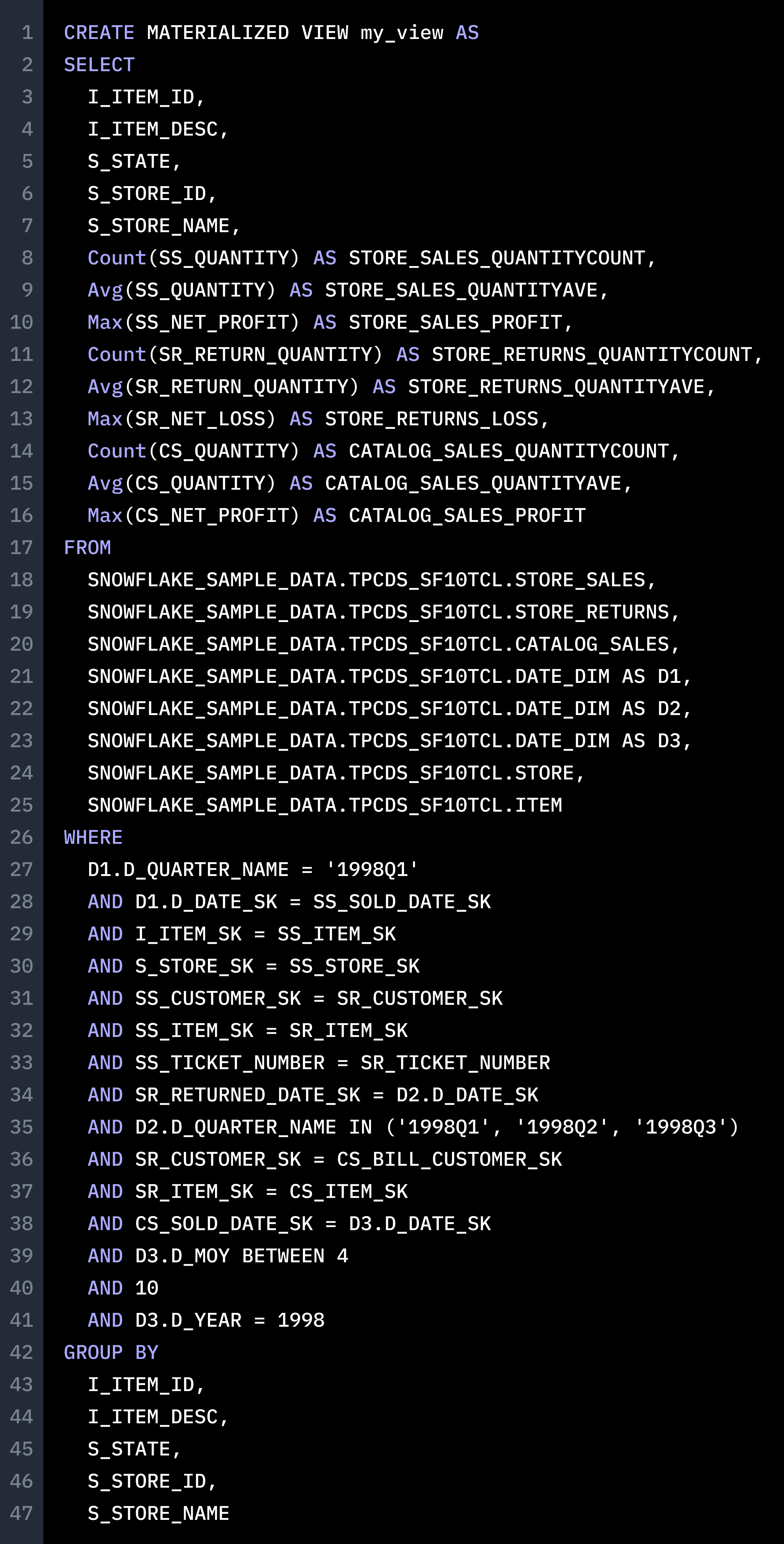
This materialized view is not reusable by the given queries, because It combines the conditions from 3 queries. The results are already filtered out, making it not suitable for pre-computation.
What We Learned
It looks like we’ve survived the inevitable march of technological progress, for now. Beyond its limitations around accuracy, we also wanted to estimate the cost of analyzing 1000 queries with ChatGPT. The above Snowflake queries are roughly 100 tokens each, and currently, the ChatGPT API costs 0.002c per 1000 tokens. So to process 1000 queries, ChatGPT would cost around $200. Most large organizations are dealing with much longer and more complex data logic across tens of thousands of queries, quickly making this approach to semantic analysis cost prohibitive.
When it comes to SQL analysis, cost and accuracy requirements make the current publicly available GPT-4 model not suitable for production environments. LLMs have a way to go yet in the SQL domain.
Subscribe to our blog to get all the latest content, including an upcoming article that dives into how our approach to semantic analysis differs from LLMs!
If you’d like to get in touch with us to see how Single Origin can reduce costs and overhead in your data stack, reach out to support@singleorigin.tech. Until next time!