Scaling Agentic Query Optimization: Uncovering Deep Insights at a Fraction of the Token Cost

This post describes how we built a query optimization agent that scales to analyze large query workloads to uncover deep insights that go beyond just the top expensive queries. The workhorse of our architecture is unique context graph built from raw metadata like query history, query profiles, schemas, table metadata, and more.
Problem
Modern AI tools make it easy enough to optimize a small set of known expensive queries. With the query text, runtime profile, and some guidance from a skilled analyst, LLMs accelerate the process of understanding, diagnosing and optimizing a single query.
But what if we want to look beyond the top expensive queries? Some of the best opportunities require analysis on the long-tail: queries that are medium-expensive can have glaring inefficiencies, or small inefficient patterns can be embedded across large swaths of queries.
The process of optimizing a single query simply doesn’t scale if your goal is to optimize an entire query workload. Two clear bottlenecks are:
- Token usage: the runtime stats for a large Spark job can occupy megabytes of text, and a large enterprise can easily accumulate terabytes of job data over the course of a day. Passing all of this to an LLM is prohibitively expensive.
- Human effort: some amount of manual review is required on LLM-based recommendations (could be a little or a lot, depending on how well the prompt is written). This adds up when trying to analyze a large set of queries.
Our solution is designed to tackle these two problems head on.
Architecture
Hard Work Behind The Scenes: Context Distillation
We start by extracting facts from raw query history, query profiles, schemas, and table metadata. For each query, we extract things like:
- Detailed column usage data, such as the filter columns used on every scan
- Query fragments, which represent the expensive regions of each query
- Query lineage information, i.e. upstream and downstream queries
- A compacted query plan, which shows the graph of operations used to execute the query with runtime metrics attached to each node. This representation elides segments of the plan that aren’t cost-significant, which makes it efficient for LLM use.

Fig 1 - Example of a compacted query plan, which elides 10 nodes from an inexpensive region
Then we compute different ways to group queries together:
- Signature: two queries share the same signature if they are structurally identical (even if they use different bind variables)
- Similarity score: every pair of query fragments has a similarity score between them. This creates a link between queries so that insights and learnings from queries in the past can apply to new ones.
- Similarity clustering: we identify groups of queries that share similar expensive fragments. This allows us to find inefficient redundancies in large query workloads.

Fig 2 - Two queries sharing a similar fragment. These queries would likely be clustered together based on this similarity.
All together, these pieces form a context graph. Queries are related to tables and columns via usage, and queries are related to other queries through lineage or similarity.
Efficiently Generating Actionable Recommendations
The context graph feeds into a suite of optimization agents that run continuously to surface the best recommendations across the entire query workload. The agents are tuned for:
- Quality: a well-written prompt reduces the rate of false positives and false negatives. One tactic we use is to apply different prompts for recommendation generation vs validation. The goal of the validation prompt is to verify that claims in the recommendation can be validated using evidence from the profile of the query analyzed (or from similar queries).
- Cost-efficiency: we use the groupings in the context graph to analyze a representative set of queries that are likely candidates for optimization. Combined with incremental processing (we don’t re-analyze query patterns if nothing has changed), this allows us to uncover deeper insights at a low cost. In a steady state, we are analyzing O(new query patterns) per day, which is often 100x more efficient than naively re-analyzing everything.
Surfacing Context and Recommendations with MCP
We surface our recommendations along with all the context APIs used to generate them via Model Context Protocol (MCP). This allows users to consume Single Origin’s data within their own AI environments, which has these advantages:
- Users retain access to all their own unique context, tools, and skills, while also having access to ours. Single Origin enhances what customers have built internally, rather than trying to replace it.
- Users can validate a recommendation by asking follow-up questions or probing on its details. AI can answer these questions by digging into the context used to generate the recommendation, which is exposed via MCP tools and hence already accessible within the same session.
- Finally, users can seamlessly transition to applying recommendations in their own codebase. This shortens the time from insight to code change, streamlining the process overall.

Fig 3 - An example recommendation
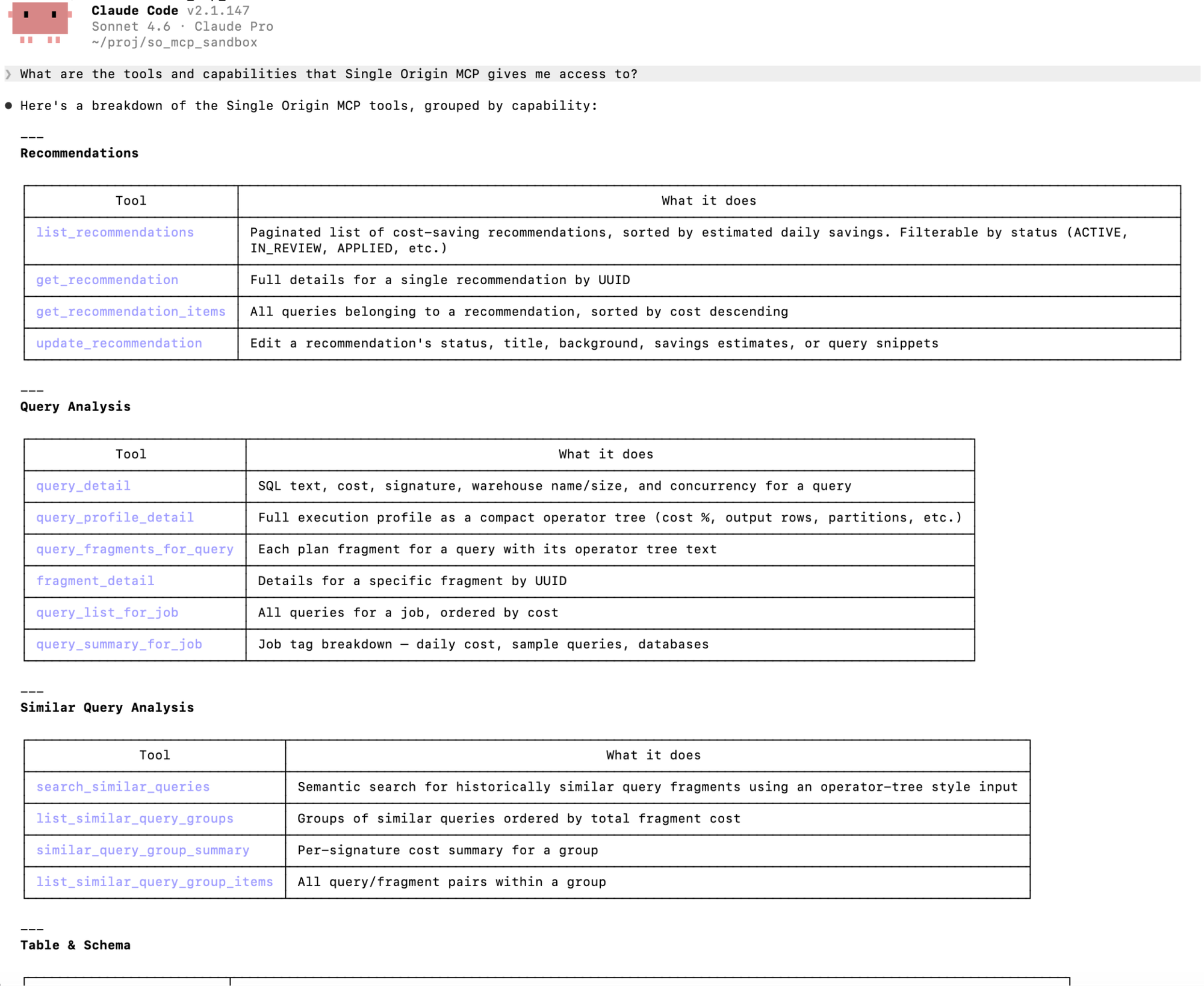
Fig 4 - Some of the context provided by Single Origin’s MCP server, summarized by Claude itself
Conclusion
Single Origin has a unique way of deriving structured context from large amounts of raw query data. This context makes it possible to find actionable optimizations across large query workloads, without breaking the budget on token usage or spending too much human effort to review LLM output. Customers who use Single Origin can plug our context and recommendations into their own AI tools, making them even more powerful and productive for query analysis.