Tame Your Data Asset Sprawl Part II: Increasing Efficiency with Single Origin

Single Origin uses Common Computation Logic to realize cost savings on the scale of 70-90%. Use our platform to save on storage and compute while maximizing the efficiency of your data organization.
Intro
In the first post of this series, we announced Cost Savings Reports in Single Origin. These reports quantify organizations' potential savings by adopting Single Origin through consolidating queries with similar semantics.
Today, we're peeking behind the curtain to reveal how Single Origin realizes performance and cost gains of 70-90%.
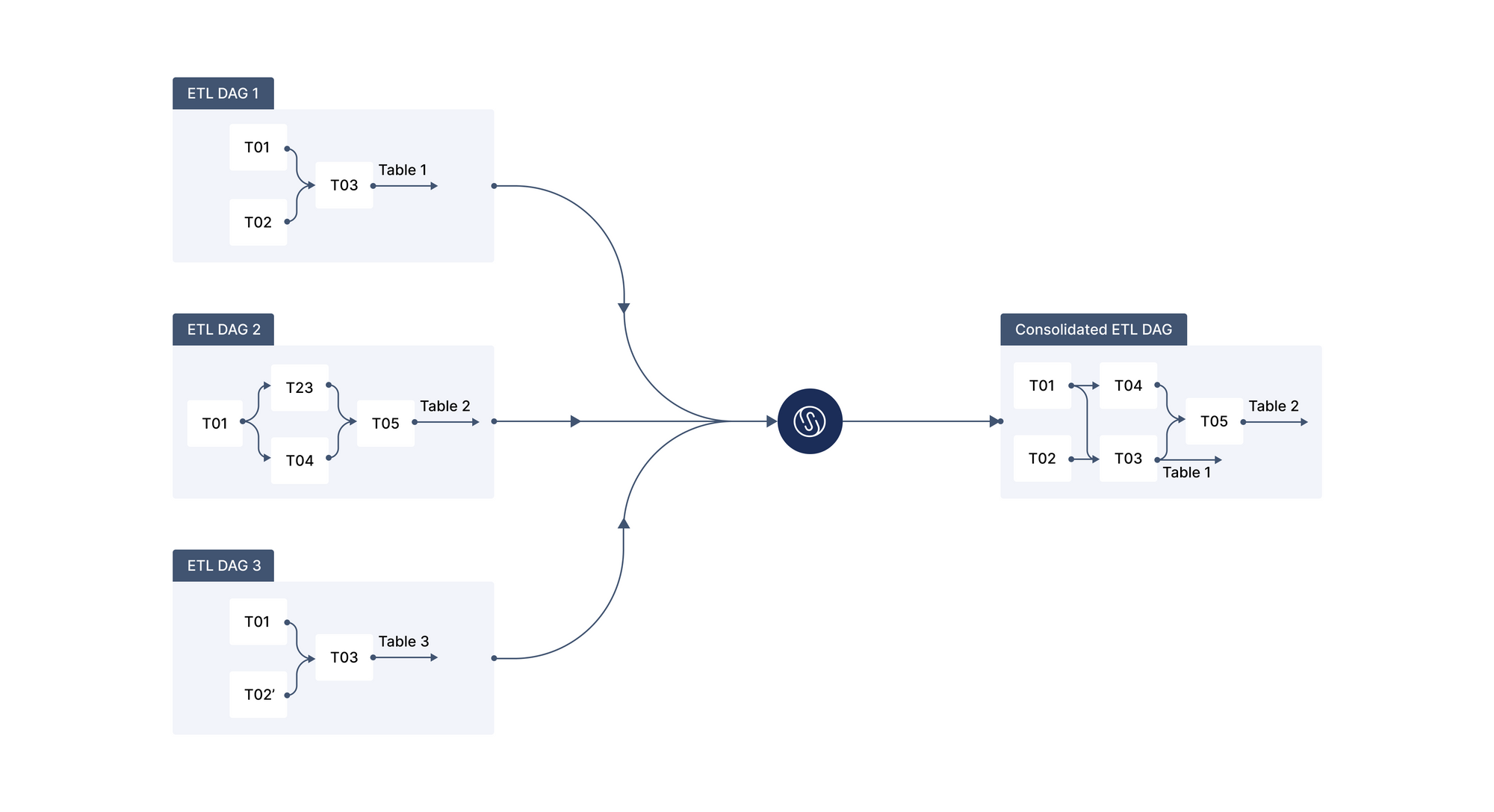
The key technical innovation is what we call "Common Computation Logic" (CCL). By deconstructing your SQL queries using our definition model, Single Origin can identify patterns and reconstruct multiple queries into a single query - aka Common Computation Logic. Single Origin can process hundreds of queries, identify similarities, and output common computation logic in minutes. By utilizing common logic, you can dramatically reduce the amount of assets you manage.
Saving on Compute with CCL
Single Origin can audit any SQL, including those that power your dashboards. When you audit your dashboard queries, Single Origin identifies overlaps in the underlying data and computation logic. This reveals opportunities to optimize your queries and pre-calculate data that is repeatedly used across multiple dashboards, significantly reducing your compute costs and improving the speed and efficiency of your data analysts.
Again, this simplification also improves your ability to properly govern your data, reducing the risk of inadvertently sharing sensitive data.
Saving on Storage with CCL
Whenever you save compute, you likely also save downstream storage. For example, consolidating multiple pipeline queries can be extremely valuable when they share similar logic. This process streamlines your operations and reduces your overall ongoing storage requirements. Removing extraneous tables generated by pipeline queries helps to simplify your data lineage as well, making it easier to govern and anticipate potential issues when things change.
Single Origin's Common Computation Logic is an excellent tool for finding and implementing consolidation opportunities in your data pipelines.
How Do I Migrate?
At Single Origin, we don't just generate Common Computation Logic. We also rewrite your original queries and provide examples of using the common logic to generate the same data. Furthermore, if you implement CCL, when users submit queries via Single Origin that try to use the old, expensive logic, the queries are automatically rewritten and executed more efficiently using the common table.
Our goal is to make it as simple as possible for you to identify opportunities to improve your operational efficiency and take action on them. We offer guidance every step of the way so you never feel lost or unsure about what to do next.
If you want to simplify your data ecosystem and maximize your organization's efficiency, reach out today!
